Rust 权威指南
Rc<T> 类型的实例会在内部维护一个用于记录值引用次数的计数器,从而确认这个值是否仍在使用。
当你希望将堆上的一些数据分享给程序的多个部分同时使用,而又无法在编译期确定哪个部分会最后释放这些数据时,我们就可以使用 Rc<T> 类型。
需要注意的是,Rc<T> 只能被用于单线程场景中。
在引用计数上调用 Rc::clone 可以让开发者一眼就区分开“深度拷贝”与“增加引用计数”这两种完全不同的克隆行为。当你需要定位存在性能问题的代码时,就可以忽略 Rc::clone 而只需要审查剩余的深度拷贝克隆行为即可。
Rc<T> 通过不可变引用使你可以在程序的不同部分之间共享只读数据。
内部可变性 (interior mutability) 是 Rust 的设计模式之一,它允许你在只持有不可变引用的前提下对数据进行修改。
与 Rc<T> 不同,RefCell<T> 类型代表了其持有数据的唯一所有权。
对于使用一般引用和 Box<T> 的代码,Rust 会在编译阶段强制代码遵守这些借用规则。
对于使用 RefCell<T> 的代码,Rust 则只会在运行时检查这些规则,并在出现违反借用规则的情况下触发 panic 来提前中止程序。
Rust 借用规则:
- 在任何给定的时间里,你要么只能拥有一个可变引用,要么只能拥有任意数量的不可变引用
- 引用总是有效的
选择使用 Box<T>、Rc<T> 和RefCell<T>的依据:
Rc<T>允许一份数据有多个所有者,而Box<T>和RefCell<T>都只有一个所有者。Box<T>允许在编译时检查的可变或不可变借用,Rc<T>仅允许编译时检查的不可变借用,RefCell<T>允许运行时检查的可变或不可变借用- 由于
RefCell<T>允许我们在运行时检查可变借用,所以即便RefCell<T>本身是不可变的,我们仍然能够更改其中存储的值
我们会在创建不可变和可变引用时分别使用语法 & 与 &mut。对于 RefCell<T> 而言,我们需要使用 borrow 与 borrow_mut 方法来实现类似的功能,这两者都被作为 RefCell<T> 的安全接口来提供给用户。borrow 方法和 borrow_mut 方法会分别返回 Ref<T> 与 RefMut<T> 这两种智能指针。由于这两种智能指针都实现了 Deref,所以我们可以把它们当作一般的引用来对待。
RefCell<T> 会记录当前存在多少个活跃的 Ref<T> 和 RefMut<T> 智能指针。每次调用 borrow 方法时,RefCell<T> 会将活跃的不可变借用计数加 1,并且在任何一个 Ref<T> 的值离开作用域被释放时,不可变借用计数将减 1。RefCell<T> 会基于这一技术来维护和编译器同样的借用检查规则:在任何一个给定的时间里,它只允许你拥有多个不可变借用或一个可变借用。
将 RefCell<T> 和 Rc<T> 结合使用是一种很常见的用法:
Rc<T>允许多个所有者持有同一数据,但只能提供针对数据的不可变访问- 如果我们在
Rc<T>内存储了RefCell<T>,那么就可以定义出拥有多个所有者且能够进行修改的值了
消息队列高手课
使用内存作为缓存来加速应用程序的访问速度,是几乎所有高性能系统都会采用的方法。
读缓存 vs 读写缓存:
区别就是,在更新数据的时候,是否经过缓存。
读写缓存的这种设计,它天然就是不可靠的,是一种牺牲数据一致性换取性能的设计。
为什么 Kafka 可以使用 PageCache 来提升它的性能呢?
这是由消息队列的一些特点决定的。
- 消息队列它的读写比例大致是 1:1,因为,大部分我们用消息队列都是一收一发这样使用。这种读写比例,只读缓存既无法给写加速,读的加速效果也有限,并不能提升多少性能
- Kafka 它并不是只靠磁盘来保证数据的可靠性,它更依赖的是,在不同节点上的多副本来解决数据可靠性问题,这样即使某个服务器掉电丢失一部分文件内容,它也可以从其他节点上找到正确的数据,不会丢消息。
- PageCache 这个读写缓存是操作系统实现的,Kafka 只要按照正确的姿势来使用就好了,不涉及到实现复杂度的问题。
不同于消息队列,我们开发的大部分业务类应用程序,读写比都是严重不均衡的,一般读的数据的频次会都会远高于写数据的频次。从经验值来看,读次数一般都是写次数的几倍到几十倍。这种情况下,使用只读缓存来加速系统才是非常明智的选择。
缓存命中 vs 缓存穿透:
- 当应用程序要访问某些数据的时候,如果这些数据在缓存中,那直接访问缓存中的数据就可以了,这次访问的速度是很快的,这种情况我们称为一次缓存命中
- 如果这些数据不在缓存中,那只能去磁盘中访问数据,就会比较慢。这种情况我们称为“缓存穿透”
Kafka 使用的 PageCache,是由 Linux 内核实现的,它的置换算法的就是一种 LRU 的变种算法:LRU 2Q。
按照读写性质,可以分为读写缓存和只读缓存,读写缓存实现起来非常复杂,并且只在消息队列等少数情况下适用。只读缓存适用的范围更广,实现起来也更简单。
只读缓存如何来更新缓存:
- 在更新数据的同时去更新缓存
- 定期来更新全部缓存
- 给缓存中的每个数据设置一个有效期,让它自然过期以达到更新的目的
这三种方法在更新的及时性上和实现的复杂度这两方面,都是依次递减的,你可以按需选择。
后端技术面试 38 讲
设计模式的精髓在于对面向对象编程特性之一——多态的灵活应用,而多态正是面向对象编程的本质所在。
在面向对象的编程语言中,多态非常简单:
子类实现父类或者接口的抽象方法,程序使用抽象父类或者接口编程,运行期注入不同的子类,程序就表现出不同的形态,是为多态。
这样做最大的好处就是软件编程时的实现无关性,程序针对接口和抽象类编程,而不需要关心具体实现是什么。
多态还颠覆了程序模块间的依赖关系:
- 在习惯的编程思维中,如果 A 模块调用 B 模块,那么 A 模块必须依赖 B 模块,也就是说,在 A 模块的代码中必须 import 或者 using B 模块的代码
- 通过使用多态的特性,我们可以将这个依赖关系倒置,也就是:A 模块调用 B 模块,A 模块却可以不依赖 B 模块,反而是 B 模块依赖 A 模块
准确地说,B 模块也没有依赖 A 模块,而是依赖 A 模块定义的抽象接口:
- A 模块针对抽象接口编程,调用抽象接口,B 模块实现抽象接口
- 在程序运行期将 B 模块注入 A 模块,就使得 A 模块调用 B 模块,却没有依赖 B 模块
多态常常使面向对象编程表现出神奇的特性,而多态正是面向对象编程的本质所在。正是多态,使得面向对象编程和以往的编程方式有了巨大的不同。
模式是可重复的解决方案,人们在编程实践中发现,有些问题是重复出现的,虽然场景各有不同,但是问题的本质是一样的,而解决这些问题的方法也是可以重复使用的。人们把这些可以重复使用的编程方法称为设计模式。设计模式的精髓就是对多态的灵活应用。
装饰模式
装饰模式最大的特点是,通过类的构造函数传入一个同类对象,也就是每个类实现的接口和构造函数传入的对象是同一个接口:
|
|
设计模式不仅仅包括《设计模式》这本书里讲到的 23 种设计模式,只要可重复用于解决某个问题场景的设计方案都可以被称为设计模式。
高并发架构实战课
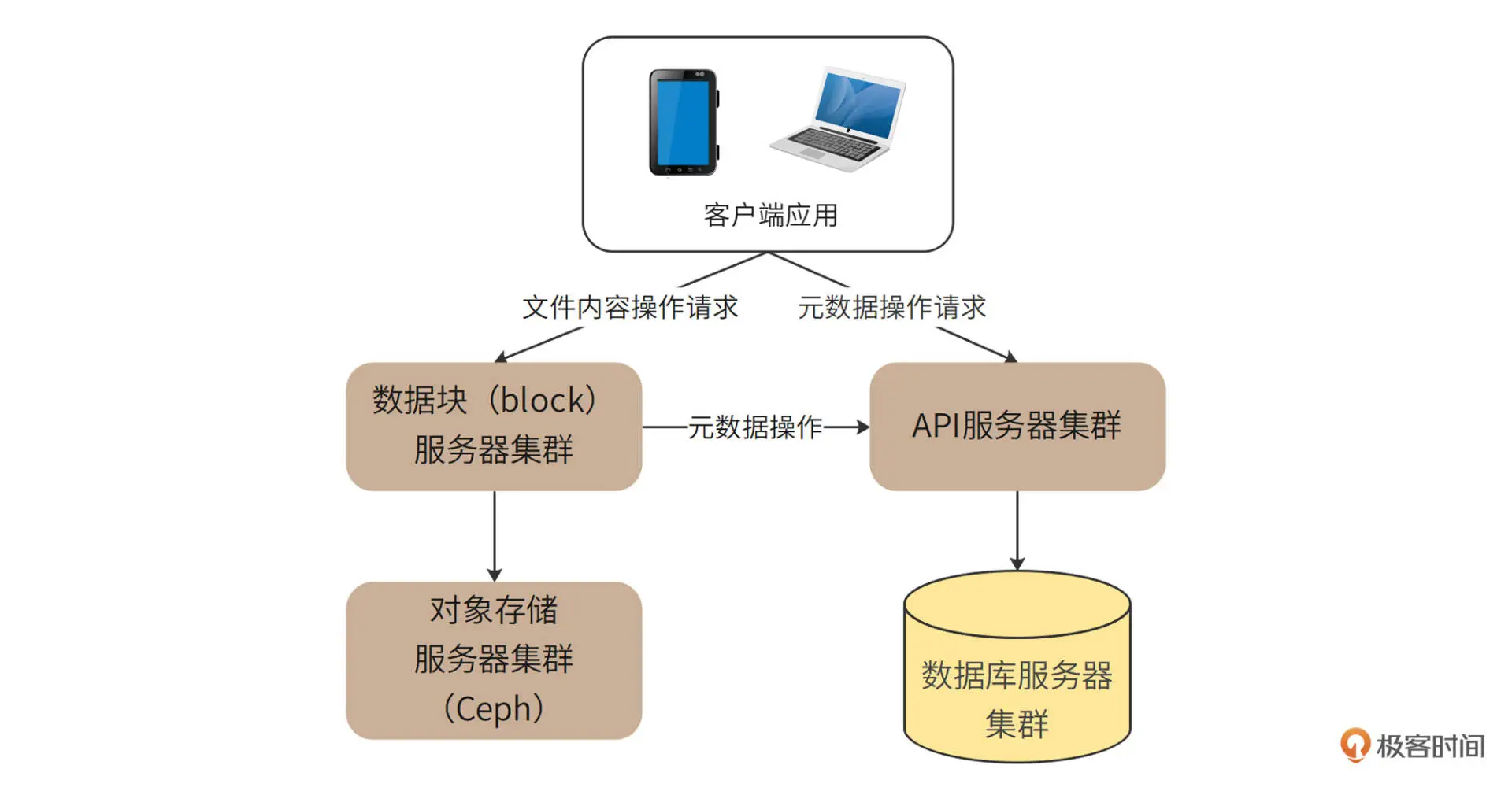
由于 DBox 是一个互联网应用,出于安全和访问管理的目的,并不适合由客户端直接访问存储元数据的数据库和存储文件内容的存储集群,而是通过 API 服务器集群和数据块服务器集群分别进行访问管理。整体架构如下图:
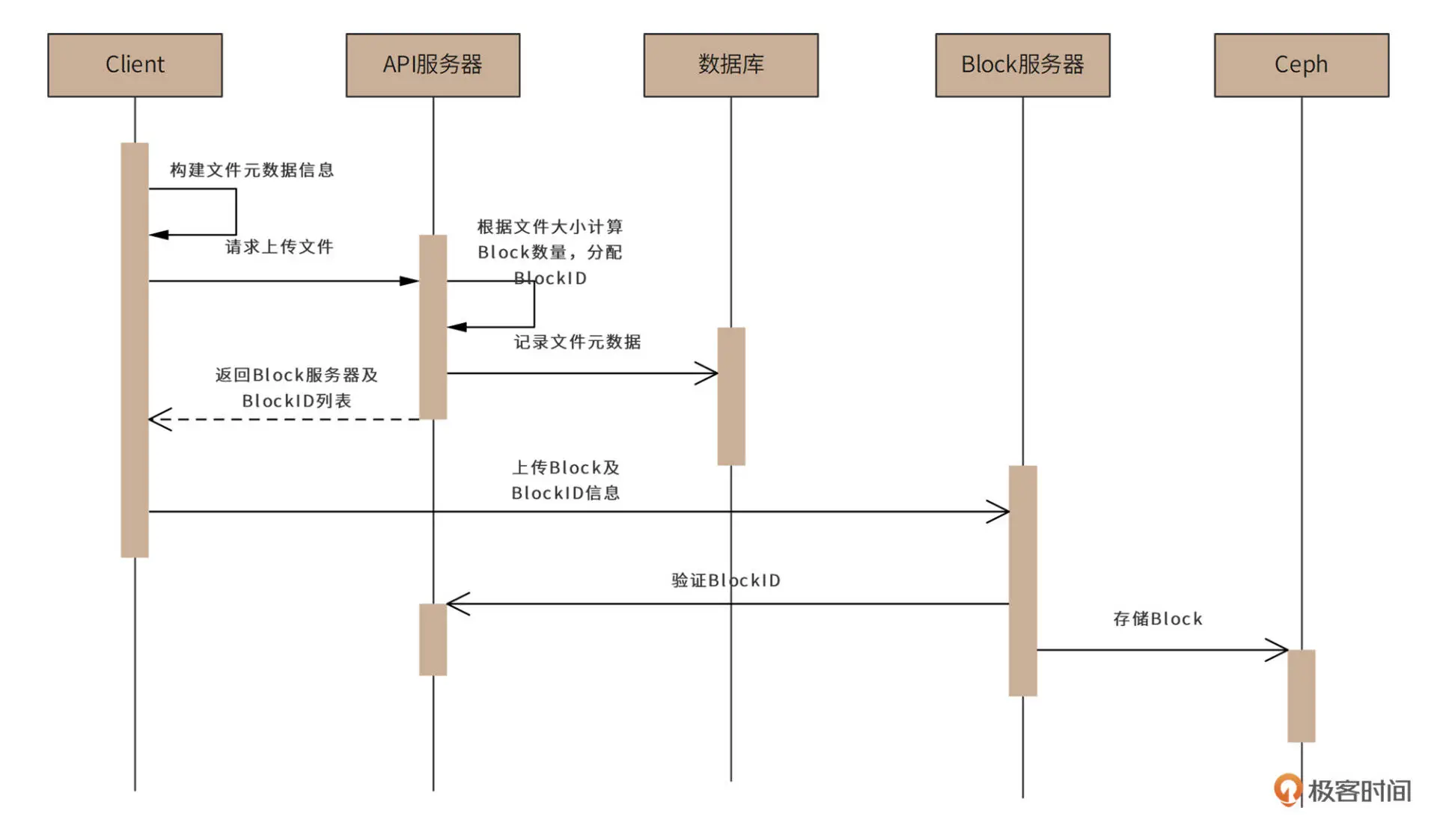
用户上传文件的时序图如下:
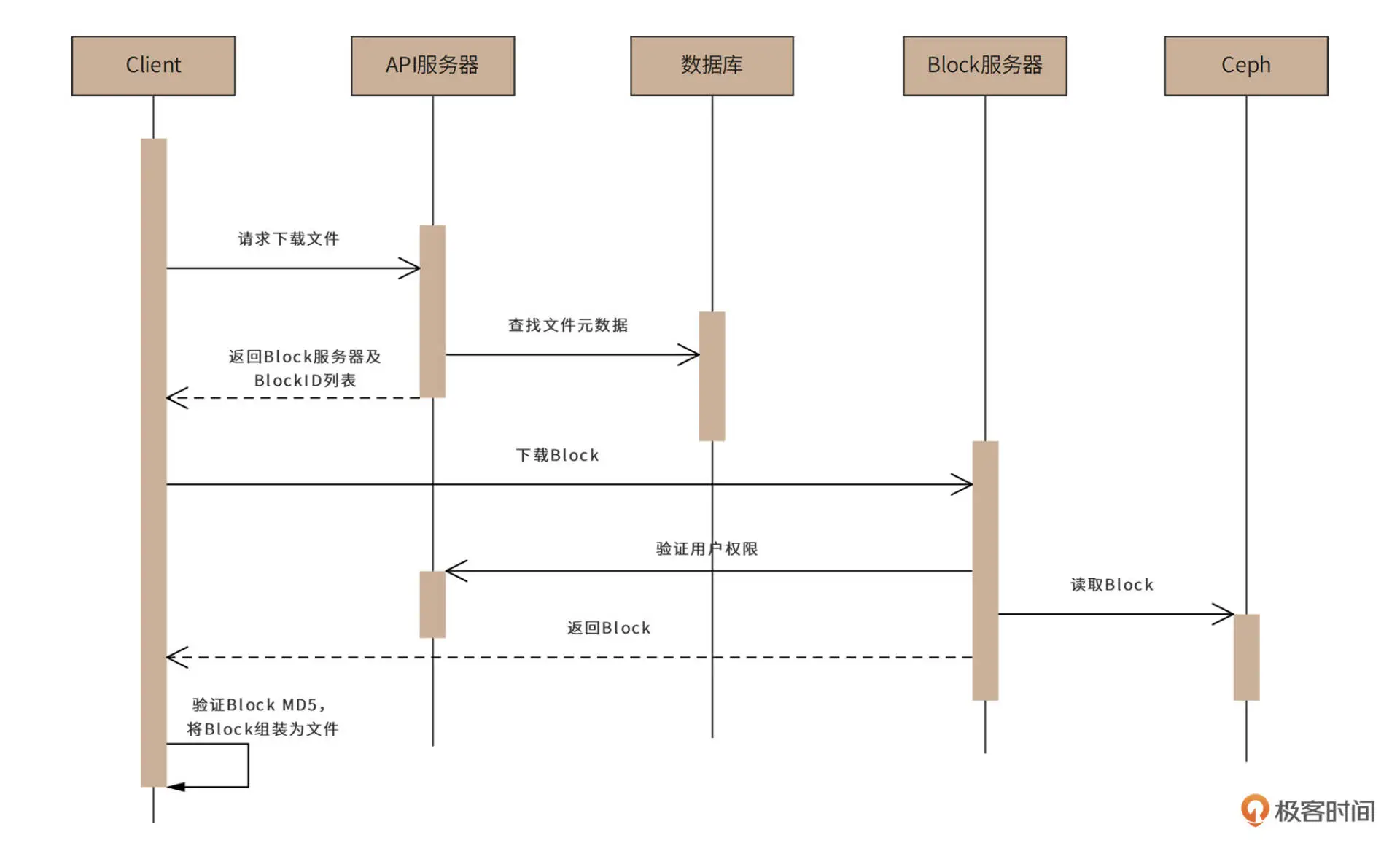
用户下载文件的时序图如下:
 数据表设计:
数据表设计:
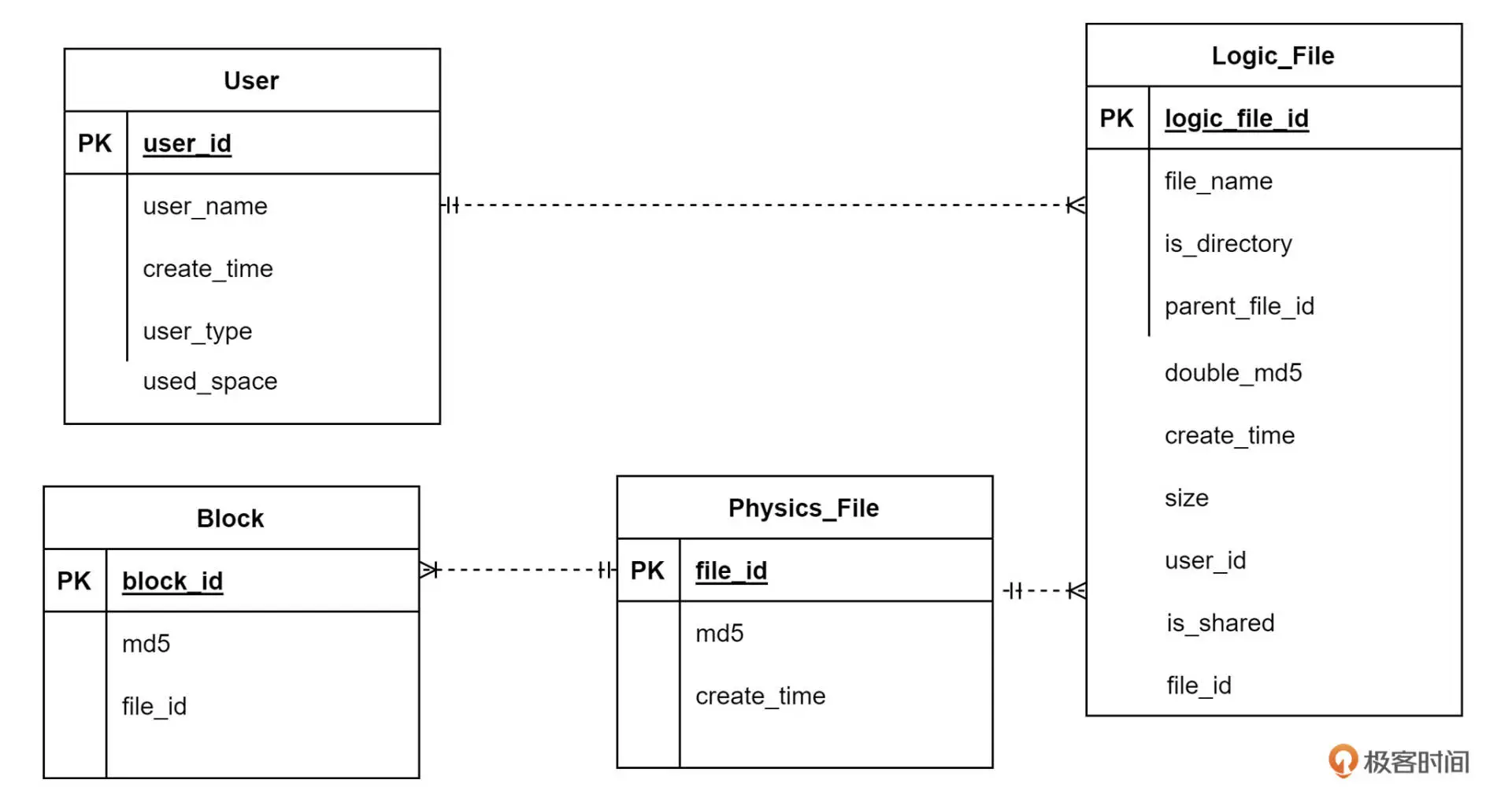
Logic_File 中字段 double_md5 记录了文件头 256KB 的 MD5、文件 MD5 两个数据拼接后的数据,而 size 记录了文件长度,只有这两个字段都相同才会启用秒传。
计算 MD5 可能会发生 Hash 冲突,也就是不同文件算出来的 MD5 值是相同的,这样会导致 DBox 误判,将本不相同的文件关联到一个物理文件上。不但会使上传者丢失自己的文件,还会被黑客利用:上传一个和目标文件 MD5 相同的文件,然后就可以下载目标文件了。
- DBox 需要通过更多信息判断文件是否相同:只有文件长度、文件开头 256KB 的 MD5 值、文件的 MD5 值,三个值都相同,才会认为文件相同
- 当文件长度小于 256KB,则直接上传文件,不启用秒传功能
架构师按照职责,可以分成两种:
- 一种是应用系统架构师,负责设计、开发类似网盘、爬虫这样的应用系统
- 应用架构师需要掌握的技术栈更加广泛,要能够掌握各种基础设施技术的特性,并能根据业务特点选择最合适的方案
- 另一种是基础设施架构师,负责设计、开发类似 Ceph、HDFS 这样的基础设施系统
- 基础设施架构师需要的技术栈更加深入,需要掌握计算机软硬件更深入的知识,才能开发出一个稳定的基础技术产品
我们为什么睡觉
在睡觉之前,参与者从海马体的短期存储位置获取记忆,经过整夜的睡眠后,参与者此时会从位于大脑顶部的新皮层处获取同一信息。
在一夜的睡眠之后,你可以重新获得睡前想不起来的记忆。
只有在非快速眼动睡眠期间,施加与大脑本身缓慢如诵经般的节奏同步的刺激,才能实现记忆力的提高。
遗忘不仅删除了我们不再需要的存储信息,也降低了检索我们想要保留的记忆所需的大脑资源睡眠可以帮助你保留你所需要的一切,而不是保留不需要的东西,从而降低回忆时的难度。
忘记是我们为记住付出的代价。
断舍离
也许应该是熟练,加上睡眠,才能生巧?
光是熟练,并不能生巧。而是练习后,再加上一夜的睡眠,才能通向完美。
正是在早晨的最后两个小时——即睡眠中脑电波活动最为丰富的时间——中产生的那些美妙的睡眠纺锤波的数量与“离线”记忆的提升有关。
睡眠的最后两个小时恰恰是我们许多人认为可以节省下来,从而早早开始新的一天的时间。结果,我们错过了早上这场睡眠纺锤波的盛宴。
学校应该让学生多睡觉,初高中的早自习应该取消。