后端技术面试 38 讲
微服务不同于分布式缓存、分布式消息队列或者分布式数据库这些技术,这些技术相对说来是比较“纯粹”的技术,和业务的耦合关系不是非常大,使用这些技术的场景也比较明确。而微服务本身和业务强相关,如果业务关系没梳理好,模块设计不清晰,使用微服务架构很可能得不偿失,带来各种挫折。
实施微服务的关注点应该遵循以下一个倒三角模型:
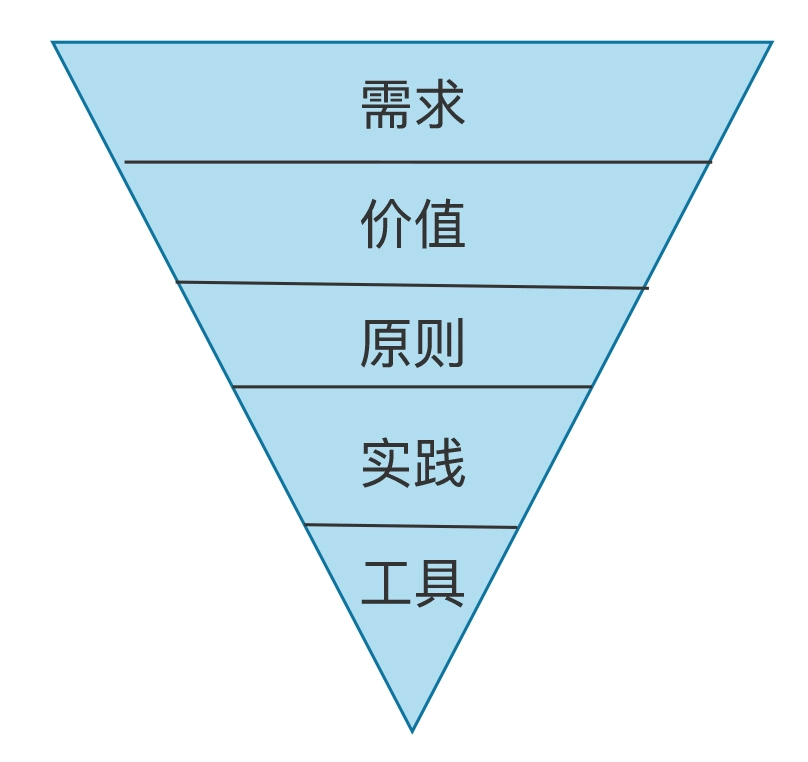
- 首先明确自己的需求:我们到底想用微服务达到什么样的目的?
- 需求清晰了,再去考虑具体要实现的价值
- 再根据价值构建我们的设计原则
- 根据原则寻找最佳实践
- 最后根据实践去选择最合适的工具
如果相反,先找到一个工具,然后用工具硬往上套需求,只会导致技术也没用好,业务也没做好,所有人都疲惫不堪,事情变得一团糟,最后反过来怪技术没用。
消息队列高手课
一个操作是否幂等,还跟调用顺序有关系,在线性调用情况下,具备幂等性的操作,在并发调用时,就不一定具备幂等性了。
Kafka 分区的 Leader 并不是选举出来的,而是 Controller 指定的。Kafka 使用 ZooKeeper 来监控每个分区的多个副本,如果发现某个分区的主节点宕机了,Controller 会收到 ZooKeeper 的通知,这个时候,Controller 会从 ISR 节点中选择一个节点,指定为新的 Leader。
在 Kafka 中 Controller 本身也是通过 ZooKeeper 选举产生的。举方法严格来说也不是真正的“选举”,而是一种抢占模式:
- 每个 Broker 在启动后,都会尝试在 ZooKeeper 中创建同一个临时节点:/controller,并把自身的信息写入到这个节点中
- 由于 ZooKeeper 它是一个可以保证数据一致性的分布式存储,所以,集群中只会有一个 Broker 抢到这个临时节点,那它就是 Leader 节点
- 其他没抢到 Leader 的节点,会 Watch 这个临时节点
- 如果当前的 Leader 节点宕机,所有其他节点都会收到通知,它们会开始新一轮的抢 Leader 游戏
RocketMQ/Dledger 的选举采用的是 Raft 一致性算法。
Raft vs 抢占式
优点是不需要借助外部系统,完全可以实现自我选举。
缺点就是算法实在是太复杂了,非常难实现。并且,往往集群中的节点要通过多轮投票才能达成一致,这个选举过程是比较慢的,一次选举耗时几秒甚至几十秒都有可能。
为什么大部分消息队列产品,都不使用存储计算分离的设计
消息队列不像其他的业务系统,可以直接使用一些成熟的分布式存储系统来存储消息,因为性能达不到要求。分离后的存储节点承担了之前绝大部分功能,并且增加了系统的复杂度,还降低了性能,显然是不划算的。
现在各大消息队列的 Roadmap(发展路线图):
- Kafka 在做 Kafka Streams
- Pulsar 在做 Pulsar Functions
其实大家都在不约而同的做同一件事儿,就是流计算。
现有的流计算平台,包括 Storm、Flink 和 Spark,它们的节点都是无状态的纯计算节点,是没有数据存储能力的。
- 现在的流计算平台,它很难做大量数据的聚合,并且在数据可靠性保证、数据一致性、故障恢复等方面,也做得不太好。
- 消息队列正好相反,它很好地保证了数据的可靠性、一致性,但是 Broker 只具备存储能力,没有计算的功能,数据流进去什么样,流出来还是什么样
同样是处理实时数据流的系统,一个只能计算不能存储,一个只能存储不能计算,那未来如果出现一个新的系统,既能计算也能存储,如果还能有不错的性能,是不是就会把现在的消息队列和流计算平台都给替代了?这是很有可能的。
哪些问题适合用流计算解决?
对实时产生的数据进行实时统计分析,这类场景都适合使用流计算来实现。
- 每分钟按照 IP 统计 Web 请求次数
- 电商在大促时,实时统计当前下单量
- 实时统计 App 中的埋点数据,分析营销推广效果
特别是基于时间维度的统计分析,使用流计算框架来实现是非常方便的。
无论是使用 Flink、Spark 还是其他的流计算框架,定义一个流计算的任务基本上都可以分为:定义输入、定义计算逻辑和定义输出三部分,通俗地说,也就是:数据从哪儿来,怎么计算,结果写到哪儿去,这三件事儿。
我们编写好计算任务的代码后,打包成 JAR 文件,然后通过 Flink 的客户端提交到 JobManager 上。计算任务被 Flink 解析后,会生成一个 Dataflow Graph,也叫 JobGraph,简称 DAG,这是一个有向无环图(DAG)
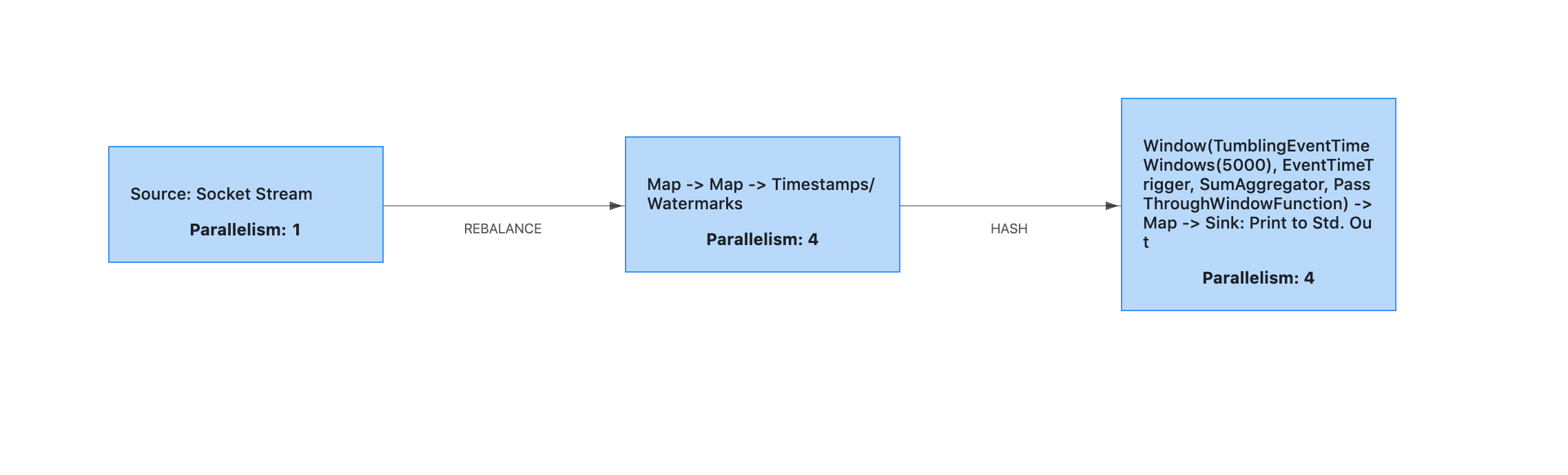 图中的每个节点是一个 Task,每个 Task 就是一个执行单元,运行在某一个 TaskManager 的进程内
图中的每个节点是一个 Task,每个 Task 就是一个执行单元,运行在某一个 TaskManager 的进程内
- 数据从 Source Task 流入,进入这个 DAG,每流过一个 Task,就被这个 Task 做一些计算和变换
- 然后数据继续流入下一个 Task,直到最后一个 Sink Task 流出 DAG,就自然完成了计算
流计算框架本身并没有什么神奇的技术,之所以能够做到非常好的性能,主要有两个原因:
- 一个是,它能自动拆分计算任务来实现并行计算
- 这个和 Hadoop 中 Map Reduce 的原理是一样的
- 另外一个原因是,流计算框架中,都内置了很多常用的计算和统计分析的算子
- 这些算子的实现都是经过很多大神级程序员反复优化过的,不仅能方便我们开发,性能上也比大多数程序员自行实现要快很多。
Flink 通过 CheckPoint 机制来定期保存计算任务的快照,这个快照中主要包含两个重要的数据:
- 整个计算任务的状态
- 这个状态主要是计算任务中,每个子任务在计算过程中需要保存的临时状态数据
- 比如,汇总了一半的数据。
- 这个状态主要是计算任务中,每个子任务在计算过程中需要保存的临时状态数据
- 数据源的位置信息
- 这个信息记录了在数据源的这个流中已经计算了哪些数据
- 如果数据源是 Kafka 的主题,这个位置信息就是 Kafka 主题中的消费位置
- 这个信息记录了在数据源的这个流中已经计算了哪些数据
有了 CheckPoint,当计算任务失败重启的时候,可以从最近的一个 CheckPoint 恢复计算任务。
Flink 通过在数据流中插入一个 Barrier(屏障)来确保 CheckPoint 中的位置和状态完全对应。
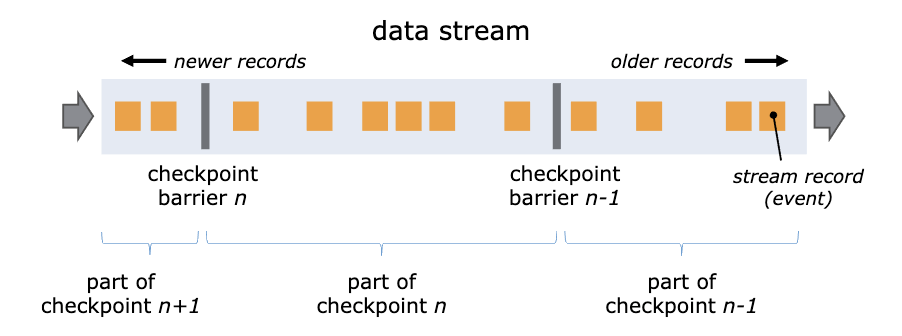 可以把 Barrier 理解为一条特殊的数据
可以把 Barrier 理解为一条特殊的数据
- Barrier 由 Flink 生成,并在数据进入计算集群时被插入到数据流中。这样,无限的数据流就被很多的 Barrier 分隔成很多段
- Barrier 在流经每个计算节点的时候,就会触发这个节点在 CheckPoint 中保存本节点的状态,如果这个节点是数据源节点,还会保存数据源的位置
端到端 Exactly Once 语义,可以保证在分布式系统中,每条数据不多不少只被处理一次。在流计算中,因为数据重复会导致计算结果错误,所以 Exactly Once 在流计算场景中尤其重要。
Kafka 和 Flink 都提供了保证 Exactly Once 的特性,配合使用可以实现端到端的 Exactly Once 语义:
- 在 Flink 中,如果节点出现故障,可以自动重启计算任务,重新分配计算节点来保证系统的可用性
- 配合 CheckPoint 机制,可以保证重启后任务的状态恢复到最后一次 CheckPoint,然后从 CheckPoint 中记录的恢复位置继续读取数据进行计算
- Flink 通过一个巧妙的 Barrier 使 CheckPoint 中恢复位置和各节点状态完全对应
- Kafka 的 Exactly Once 语义是通过它的事务和生产幂等两个特性来共同实现的
- 在配合 Flink 的时候,每个 Flink 的 CheckPoint 对应一个 Kafka 事务,只要保证 CheckPoint 和 Kafka 事务同步提交就可以实现端到端的 Exactly Once
- Flink 通过“二阶段提交”这个分布式事务的经典算法来保证 CheckPoint 和 Kafka 事务状态的一致性
高并发架构实战课
分布式爬虫通过存储服务器将爬取的网页存储到分布式文件集群 HDFS,为了提高存储效率,网页将被压缩后存储。存储的时候,网页一个文件挨着一个文件地连续存储

- 每个网页被分配得到一个 8 字节长整型 docID
- docID 之后用 2 个字节记录网页的 URL 的长度,之后 4 个字节记录压缩后网页内容数据的长度
- 之后存储 URL 字符串和压缩后的网页内容数据
读取文件的时候,先读 14 个字节的头信息,根据头信息中记录的 URL 长度和数据长度,再读取对应长度的 URL 和网页内容数据。
列表求交集最简单的实现就是双层 for 循环,但是这种算法的时间复杂度是 O(n^2),我们的网页列表长度(n)可能有千万级甚至更高,这样的计算效率太低。
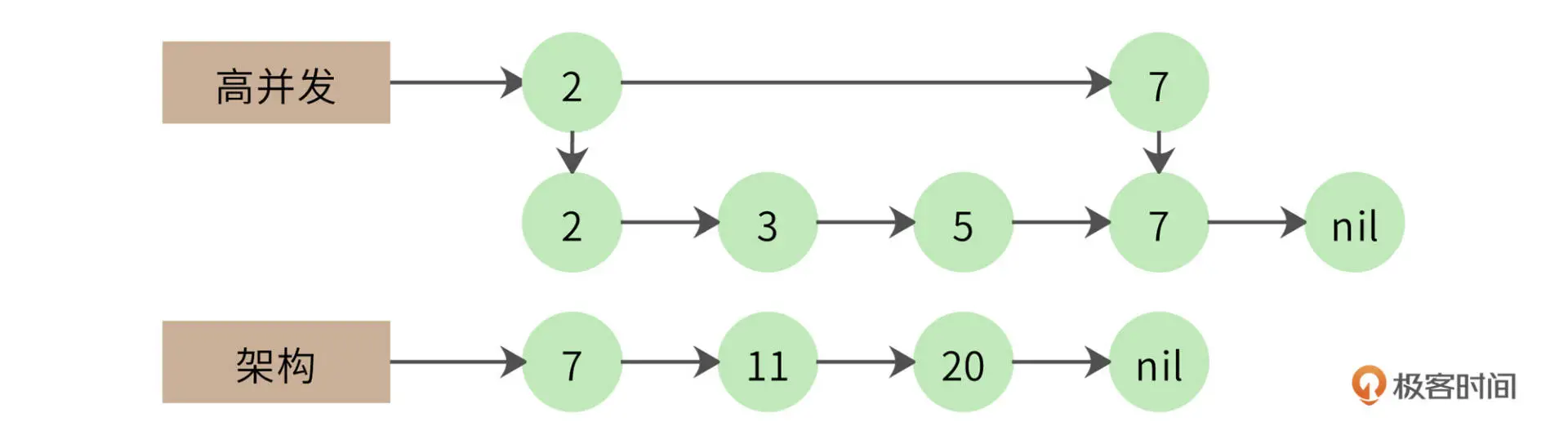
一个改进的算法是拉链法,我们将网页列表先按照 docID 的编号进行排序,得到的就是这样两个有序链表:
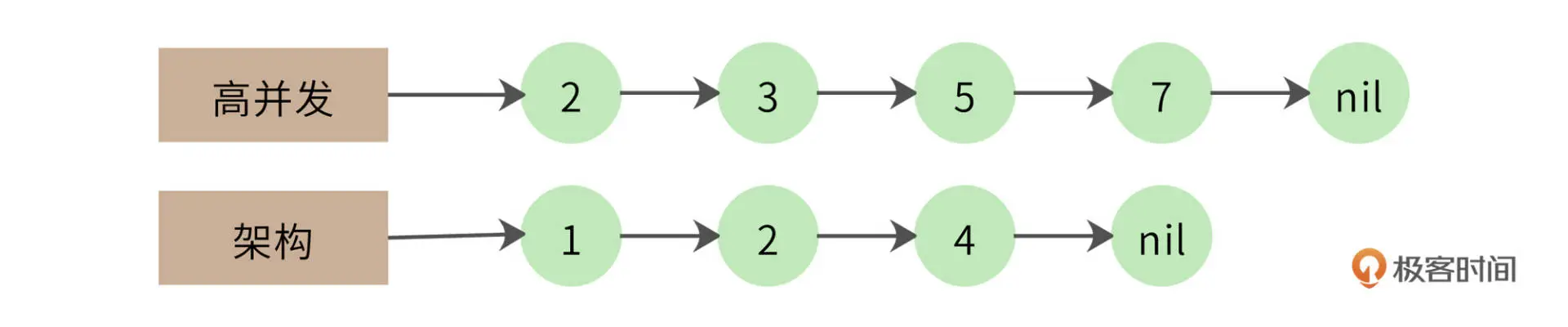
- 同时遍历两个链表,如果其中一个链表当前指向的元素小于另一个链表当前指向的元素,那么这个链表就继续向前遍历
- 如果两个链表当前指向的元素相同,该元素就是交集元素,记录在结果列表中
- 依此继续向前遍历,直到其中一个链表指向自己的尾部 nil
进一步可以实用跳表:跳表实际上是在链表上构建多级索引,在索引上遍历可以跳过底层的部分数据,我们可以利用这个特性实现链表的跳跃式比较,加快计算速度。使用跳表的交集计算时间复杂度大约是 O(log(n))。
PageRank 算法会根据网页的链接关系给网页打分。如果一个网页 A 包含另一个网页 B 的超链接,那么就认为 A 网页给 B 网页投了一票。一个网页得到的投票越多,说明自己越重要;越重要的网页给自己投票,自己也越重要。
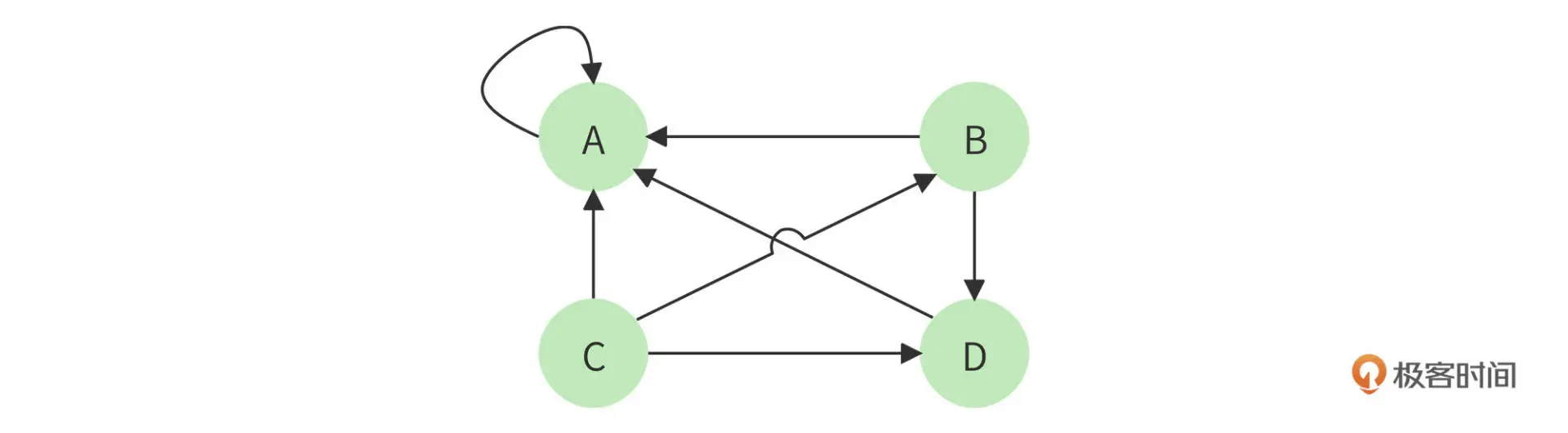
这个算法还有个问题,如果某个页面只包含指向自己的超链接,其他页面不断给它送分,而自己一分不出,随着计算执行次数越多,它的分值也就越高,这显然是不合理的。这种情况就像下图所示的,A 页面只包含指向自己的超链接。
这个算法有个问题,如果某个页面只包含指向自己的超链接,其他页面不断给它送分,而自己一分不出,随着计算执行次数越多,它的分值也就越高,这显然是不合理的。这种情况就像下图所示的,A 页面只包含指向自己的超链接。
解决方案是,设想浏览一个页面的时候,有一定概率不是点击超链接,而是在地址栏输入一个 URL 访问其他页面,表示在公式上,就是:
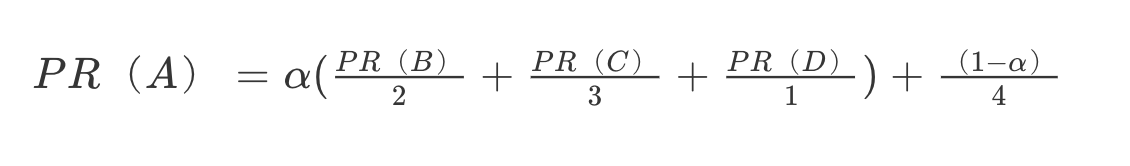 上面
上面 (1−α) 就是跳转到其他任何页面的概率,通常取经验值 0.15 (即 α 为 0.85),因为有一定概率输入的 URL 是自己的,所以加上上面公式最后一项,其中分母 4 表示所有网页的总数。
Rust 权威指南
可以使用模式的场合
match 分支
|
|
if let 条件表达式
|
|
while let 条件循环
|
|
for循环
|
|
let 语句
|
|
函数的参数
|
|
模式可失败与不可失败
模式可以被分为不可失败(irrefutable)和可失败(refutable)两种类型。
- 不可失败的模式能够匹配任何传入的值
- 函数参数、let 语句及 for 循环只接收不可失败模式
- 例如,语句 let x = 5; 中的 x 便是不可失败模式,因为它能够匹配表达式右侧所有可能的返回值
- 可失败模式则可能因为某些特定的值而匹配失败
- if let 和 while let 表达式则只接收可失败模式
- 例如,表达式 if let Some (x) = a_value 中的 Some (x) 便是可失败模式。如果 a_value 变量的值是 None 而不是 Some,那么表达式左侧的 Some (x) 模式就会发生不匹配的情况