高并发架构实战课
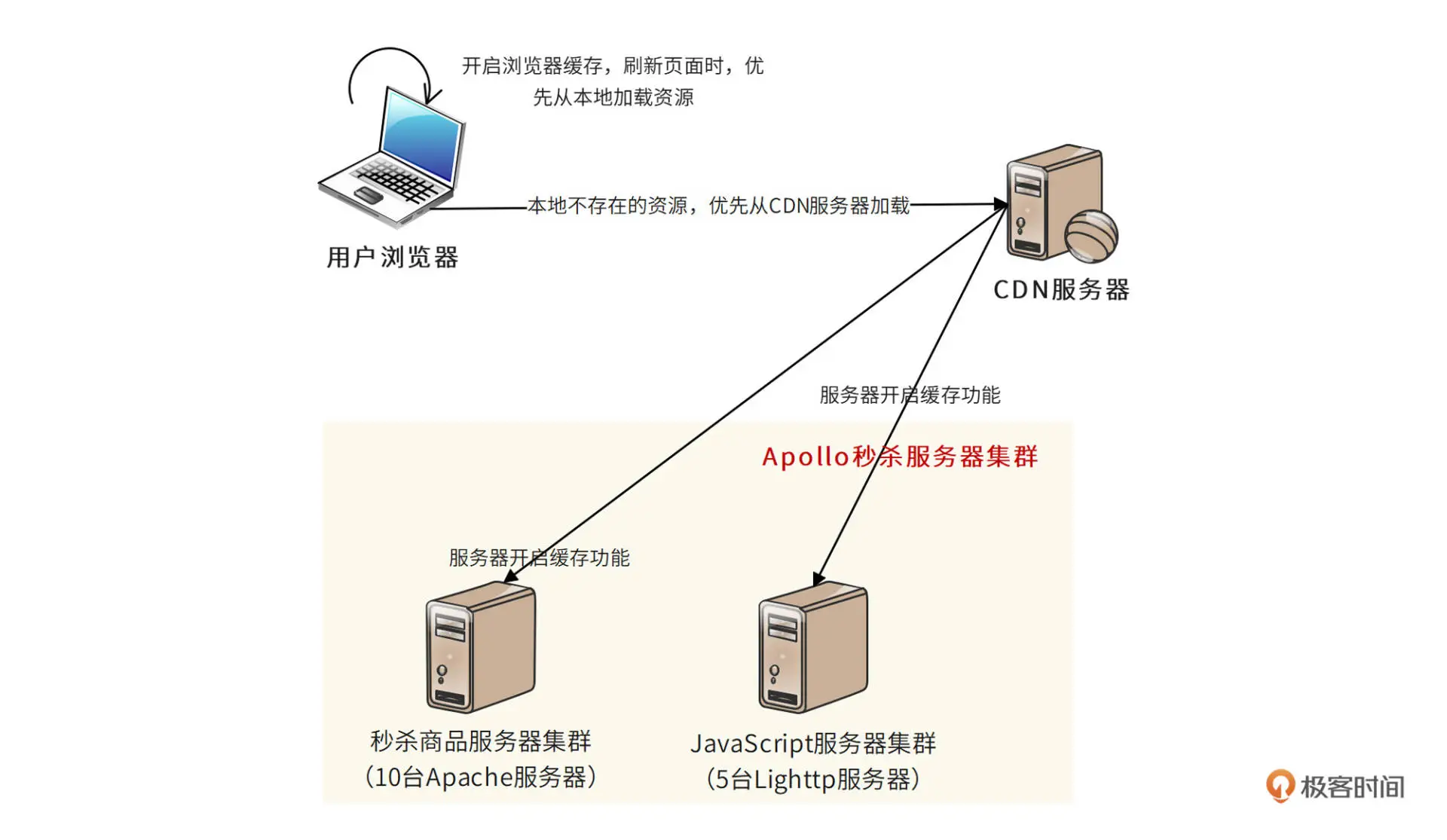
秒杀系统采用多级缓存方案,可以更有效地降低服务器的负载压力:
- 首先,浏览器尽可能在本地缓存当前页面
- 页面本身的 HTML、JavaScript、CSS、图片等内容全部开启浏览器缓存,刷新页面的时候,浏览器事实上不会向服务器提交请求,这样就避免了服务器的访问负载压力
- 其次,秒杀系统还使用 CDN 缓存
- CDN 即内容分发网络,是由网络运营服务商就近为用户提供的一种缓存服务。秒杀相关的 HTML、JavaScript、CSS、图片都可以缓存到 CDN 中,秒杀开始前,即使有部分用户新打开浏览器,也可以通过 CDN 加载到这些静态资源,不会访问服务器,又一次避免了服务器的访问负载压力
- 秒杀系统中提供 HTML、JavaScript、CSS、图片的静态资源服务器和提供商品浏览的秒杀商品服务器也要在本地开启缓存功能,进一步降低服务器的负载压力
多级缓存的秒杀系统部署图:
秒杀开始后,秒杀系统会使用一个计数器对并发请求进行限流处理:
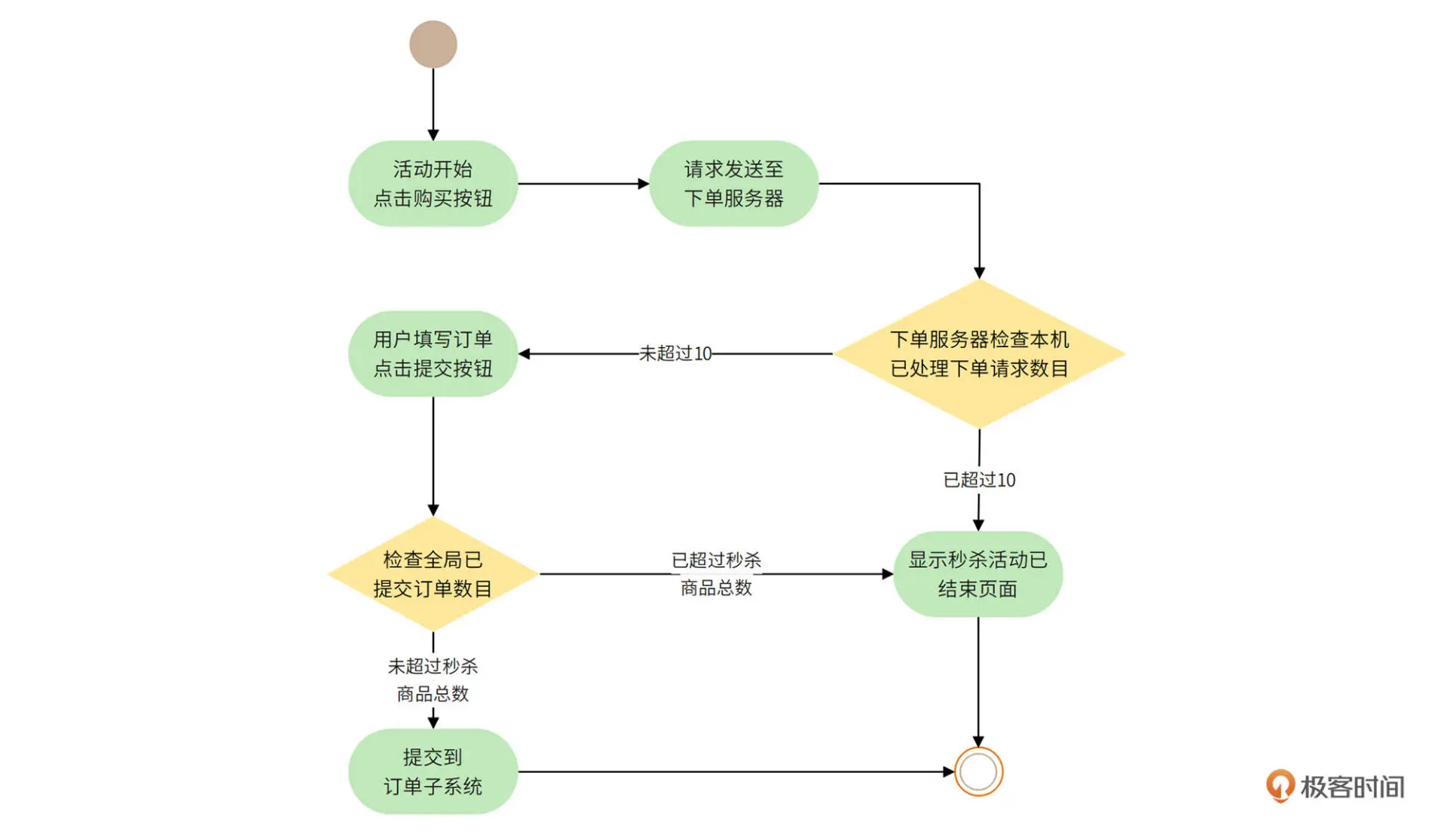
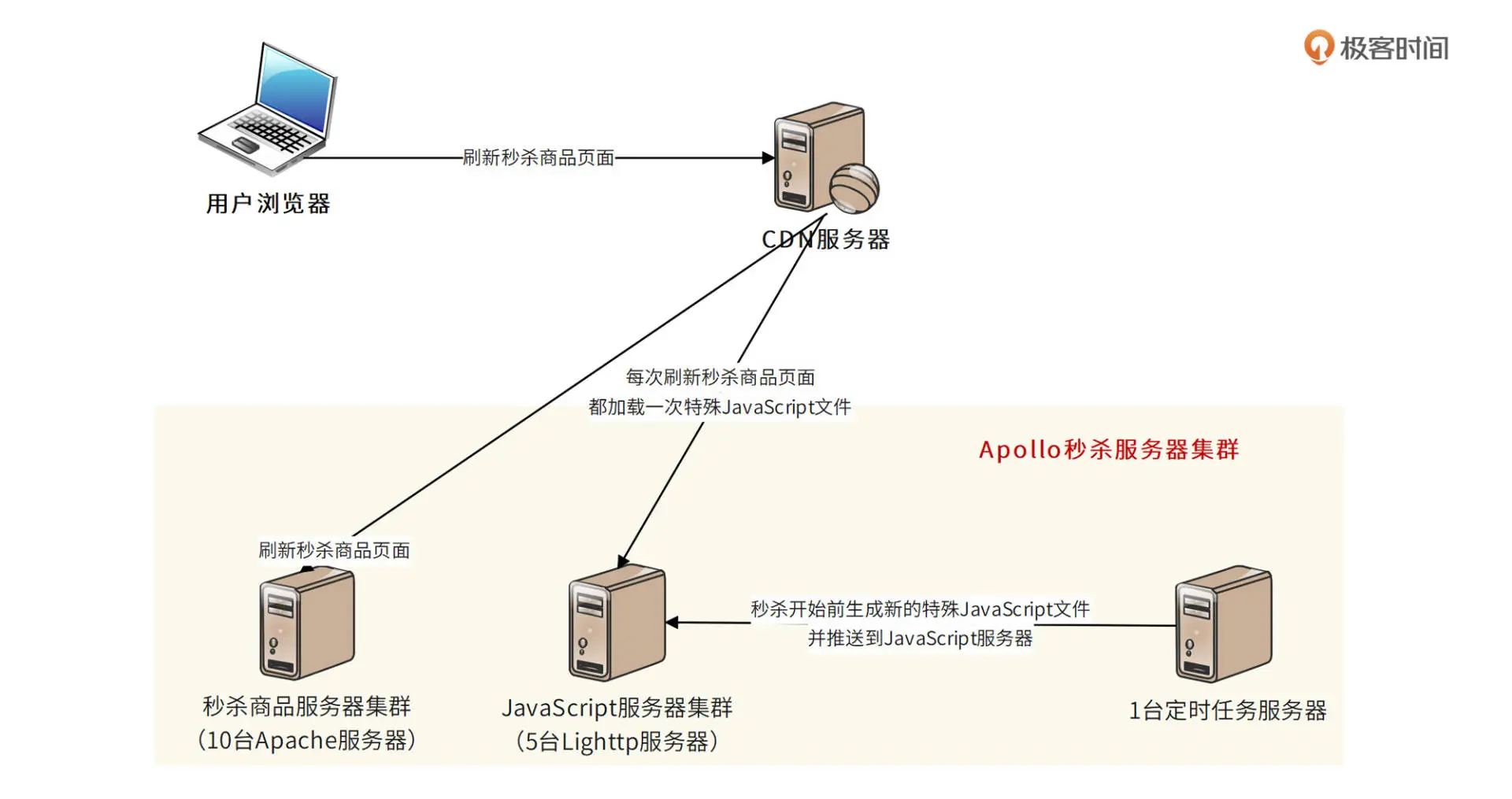
秒杀商品页面购买按钮点亮方案设计与下单 URL 下发
购买按钮只有在秒杀活动开始时才能点亮,在此之前是灰色的。
我们需要在秒杀商品静态页面中加入一个特殊的 JavaScript 文件,这个 JavaScript 文件设置为不被任何地方缓存。秒杀未开始时,该 JavaScript 文件内容为空。当秒杀开始时,定时任务会生成新的 JavaScript 文件内容,并推送到 JavaScript 服务器。
新的 JavaScript 文件包含了秒杀是否开始的标志和下单页面 URL 的随机数参数。当用户刷新页面时,新 JavaScript 文件会被用户浏览器加载,根据 JavaScript 中的参数控制秒杀按钮的点亮。当用户点击按钮时,提交表单的 URL 参数也来自这个 JavaScript 文件
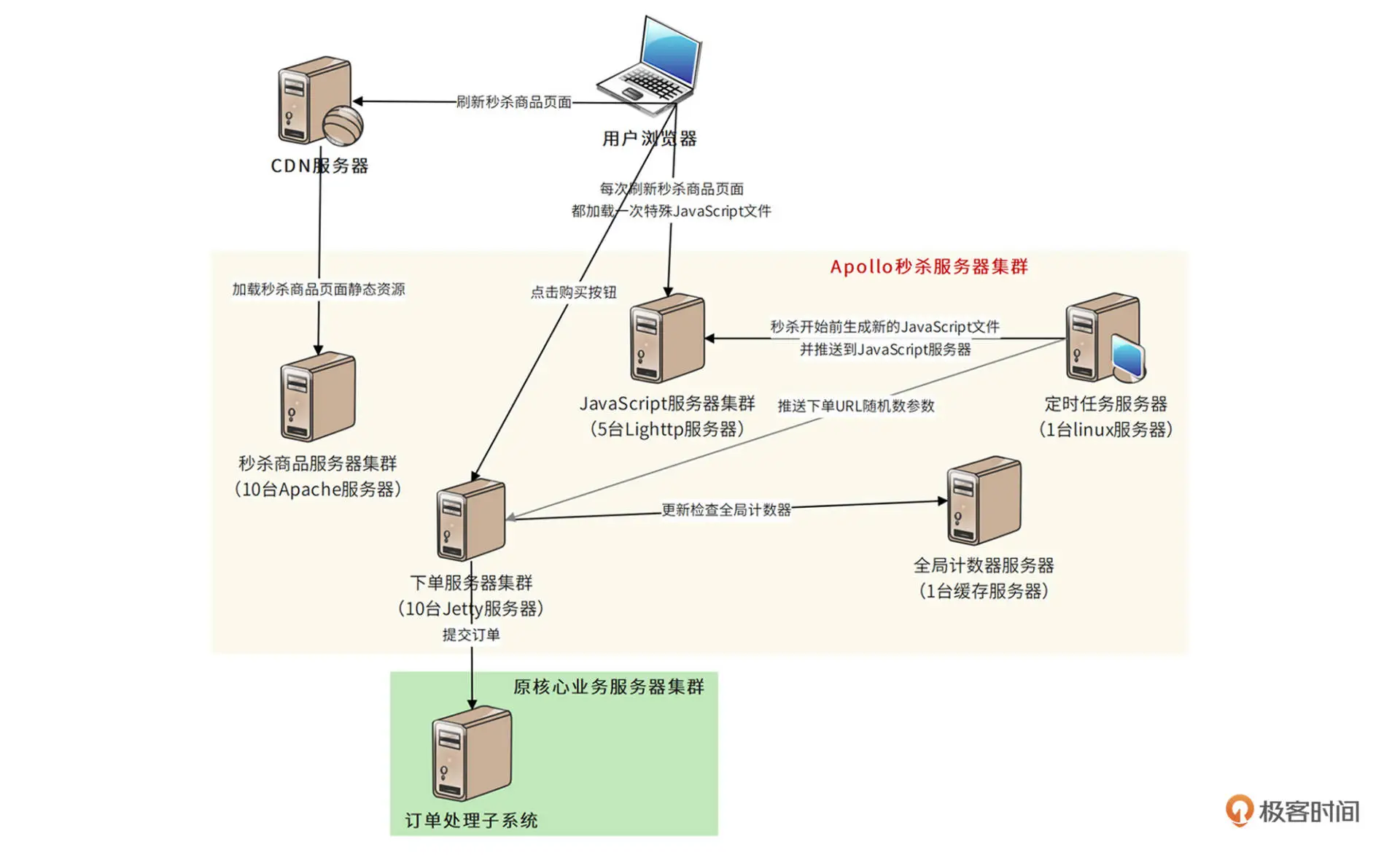
系统整体部署模型如下
对一个架构师而言,精通技术是重要的,而用技术建立起自己的信心,在关键时刻有勇气面对挑战更重要。人生的道路虽然漫长,但是紧要处可能只有几秒。这几秒是秒杀系统高并发访问高峰的那几秒,也是面对挑战迎难而上站出来的那几秒。
后端技术面试 38 讲
互联网应用的核心解决思路就是采用分布式架构,提供更多的服务器,从而提供更多的计算资源,以应对高并发带来的计算压力及资源消耗。
所谓缓存,就是将需要多次读取的数据暂存起来,这样在后面,应用程序需要多次读取的时候,就不必从数据源重复加载数据了,这样就可以降低数据源的计算负载压力,提高数据响应速度。
缓存可以分成两种
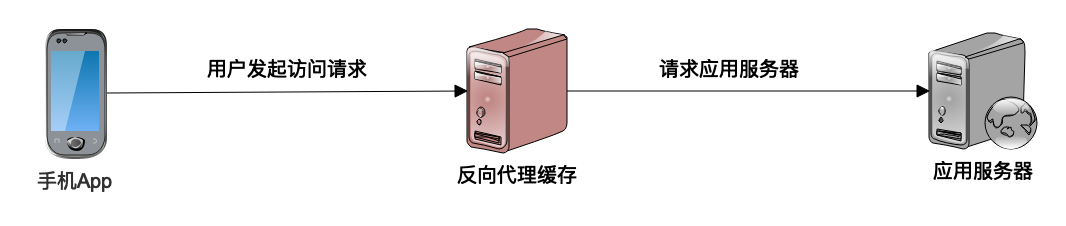
通读(read-through)缓存
应用程序访问通读缓存获取数据的时候,如果通读缓存有应用程序需要的数据,那么就返回这个数据;如果没有,那么通读缓存就自己负责访问数据源,从数据源获取数据返回给应用程序,并将这个数据缓存在自己的缓存中。这样,下次应用程序需要数据的时候,就可以通过通读缓存直接获得数据了。
 使用场景:CDN 和反向代理缓存
使用场景:CDN 和反向代理缓存
CDN(Content Delivery Network)即内容分发网络。
目前很多互联网应用大约 80% 以上的网络流量都是通过 CDN 返回的。
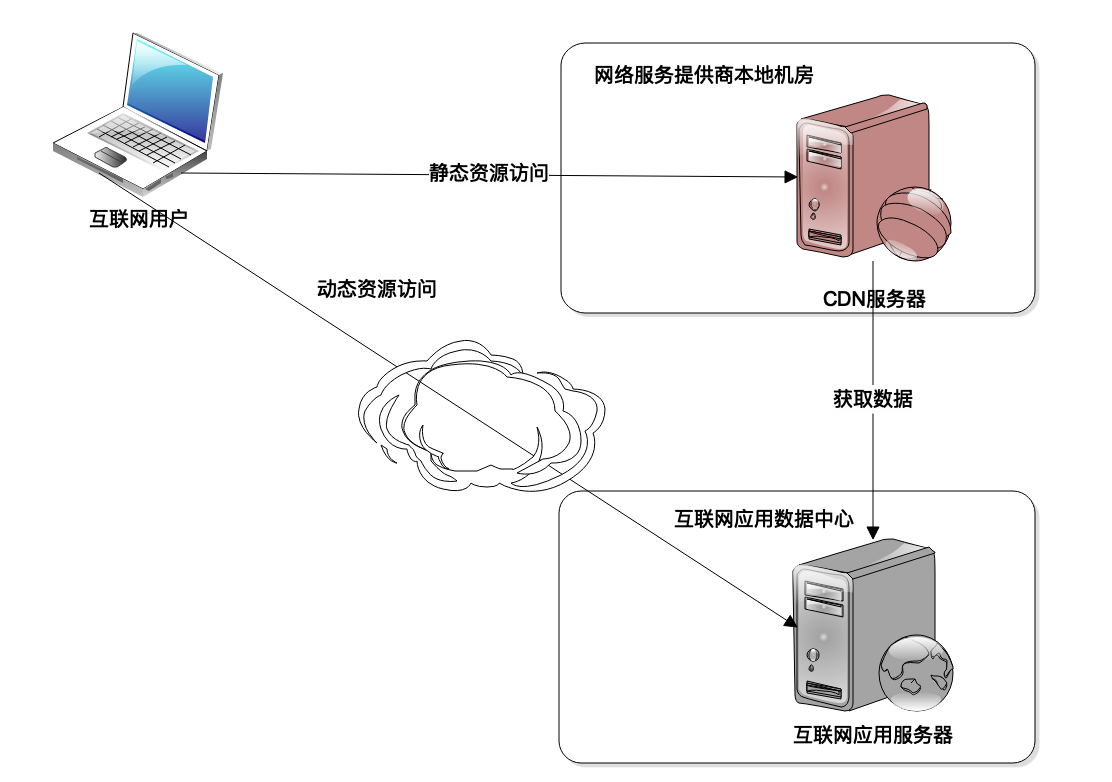
CDN 只能缓存静态数据内容,比如图片、CSS、JS、HTML 等内容。而动态的内容,比如订单查询、商品搜索结果等必须要应用服务器进行计算处理后才能获得。因此,互联网应用的静态内容和动态内容需要进行分离,静态内容和动态内容部署在不同的服务器集群上,使用不同的二级域名,即所谓的动静分离,一方面便于运维管理,另一方面也便于 CDN 进行缓存,使 CDN 只缓存静态内容。
反向代理:我们上网的时候,有时候需要通过代理上网,这个代理是代理我们的客户端上网设备。而反向代理则代理服务器,是应用程序服务器的门户,所有的网络请求都需要通过反向代理才能到达应用程序服务器。既然所有的请求都需要通过反向代理才能到达应用服务器,那么在这里加一个缓存,尽快将数据返回给用户,而不是发送给应用服务器,这就是反向代理缓存。
旁路(cache-aside)缓存
应用程序访问旁路缓存获取数据的时候,如果旁路缓存中有应用程序需要的数据,那么就返回这个数据;如果没有,就返回空(null)。应用程序需要自己从数据源读取数据,然后将这个数据写入到旁路缓存中。这样,下次应用程序需要数据的时候,就可以通过旁路缓存直接获得数据了。
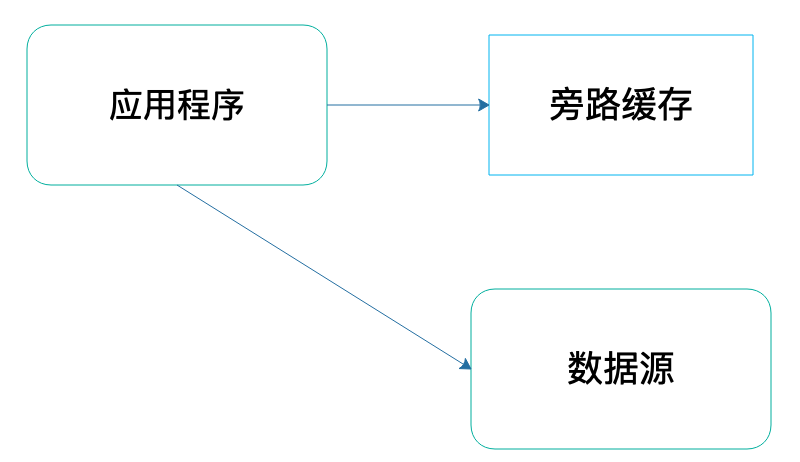 使用场景:应用程序在代码中主要使用的是对象缓存,对象缓存是一种旁路缓存。
使用场景:应用程序在代码中主要使用的是对象缓存,对象缓存是一种旁路缓存。
程序中使用的对象缓存,可以分成两种:
- 本地缓存,缓存和应用程序在同一个进程中启动,使用程序的堆空间存放缓存数据。本地缓存的响应速度快,但是缓存可以使用的内存空间相对比较小
- 分布式缓存是指将一组服务器构成一个缓存集群,共同对外提供缓存服务
使用缓存能够带来三个方面的好处:
- 的数据通常存储在内存中,距离使用数据的应用也更近一点,因此相比从硬盘上获取,或者从远程网络上获取,它获取数据的速度更快一点,响应时间更快,性能表现更好。
- 缓存的数据通常是计算结果数据,比如对象缓存中,通常存放经过计算加工的结果对象,如果缓存不命中,那么就需要从数据库中获取原始数据,然后进行计算加工才能得到结果对象,因此使用缓存可以减少 CPU 的计算消耗,节省计算资源,同样也加快了处理的速度。
- 通过对象缓存获取数据,可以降低数据库的负载压力;通过 CDN、反向代理等通读缓存获取数据,可以降低服务器的负载压力。这些被释放出来的计算资源,可以提供给其他更有需要的计算场景,比如写数据的场景,间接提高整个系统的处理能力。
数据脏读
缓存的数据来自数据源,如果数据源中的数据被修改了,那么缓存中的数据就变成脏数据了。
主要解决办法有两个:
- 过期失效,每次写入缓存中的数据都标记其失效时间,在读取缓存的时候,检查数据是否已经过期失效,如果失效,就重新从数据源获取数据
- 失效通知,应用程序更新数据源的数据,同时发送通知,将该数据从缓存中清除。失效通知看起来数据更新更加及时,但是实践中,更多使用的还是过期失效
如果缓存的数据没有热点,写入缓存的数据很难被重复读取,那么使用缓存就不是很有必要了。
对于一个典型的互联网应用而言,使用缓存可以解决绝大部分的性能问题,如果需要优化软件性能,那么可以优先考虑哪里可以使用缓存改善性能。
消息队列高手课
在集群模式下,NameServer 各节点之间是不需要任何通信的,也不会通过任何方式互相感知,每个节点都可以独立提供全部服务。
在 RocketMQ 集群中,NameServer 是如何配合 Broker、生产者和消费者一起工作的。
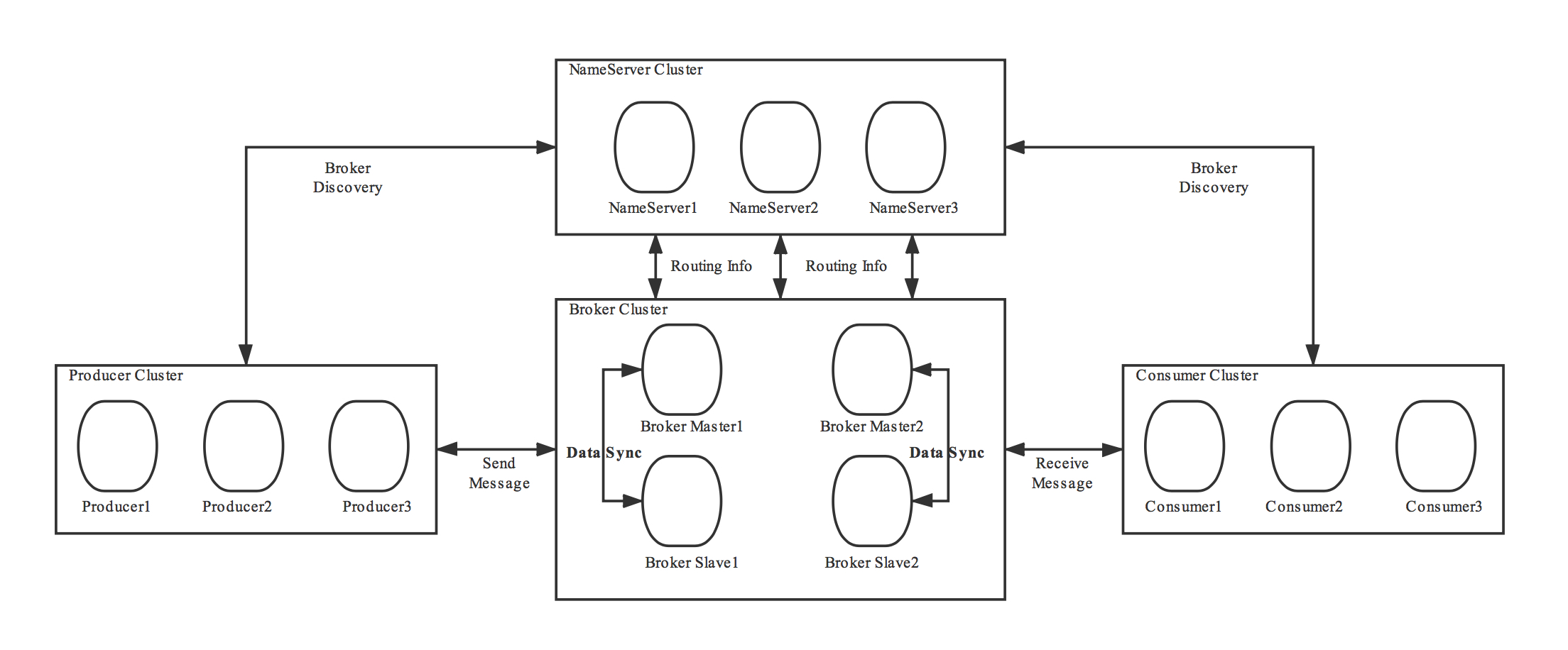 每个 Broker 都需要和所有的 NameServer 节点进行通信。当 Broker 保存的 Topic 信息发生变化的时候,它会主动通知所有的 NameServer 更新路由信息,为了保证数据一致性,Broker 还会定时给所有的 NameServer 节点上报路由信息。这个上报路由信息的 RPC 请求,也同时起到 Broker 与 NameServer 之间的心跳作用,NameServer 依靠这个心跳来确定 Broker 的健康状态。
每个 Broker 都需要和所有的 NameServer 节点进行通信。当 Broker 保存的 Topic 信息发生变化的时候,它会主动通知所有的 NameServer 更新路由信息,为了保证数据一致性,Broker 还会定时给所有的 NameServer 节点上报路由信息。这个上报路由信息的 RPC 请求,也同时起到 Broker 与 NameServer 之间的心跳作用,NameServer 依靠这个心跳来确定 Broker 的健康状态。
客户端在生产或消费某个主题的消息之前,会先从 NameServer 上查询这个主题的路由信息,然后根据路由信息获取到当前主题和队列对应的 Broker 物理地址,再连接到 Broker 节点上进行生产或消费。
RouteInfoManager 类中保存了所有的路由信息,这些路由信息都是保存在内存中,并且没有持久化的。
|
|
- topicQueueTable 保存的是主题和队列信息,其中每个队列信息对应的类 QueueData 中,还保存了 brokerName。
- brokerAddrTable 中保存了集群中每个 brokerName 对应 Broker 信息
对于客户端来说,无论是生产者还是消费者,通过主题来寻找 Broker 的流程是一样的,使用的也是同一份实现。客户端在启动后,会启动一个定时器,定期从 NameServer 上拉取相关主题的路由信息,然后缓存在本地内存中,在需要的时候使用。
NameServer 在集群中起到的一个核心作用就是,为客户端提供路由信息,帮助客户端找到对应的 Broker。
每个 NameServer 节点上都保存了集群所有 Broker 的路由信息,可以独立提供服务。Broker 会与所有 NameServer 节点建立长连接,定期上报 Broker 的路由信息。客户端会选择连接某一个 NameServer 节点,定期获取订阅主题的路由信息,用于 Broker 寻址。
给客户端提供路由寻址服务的方式可以有两种:
- 一种是客户端直接连接 NamingService 服务查询路由信息
- 另一种是,客户端连接集群内任意节点查询路由信息,节点再从自身的缓存或者从 NamingService 上进行查询
Rust 权威指南
现有的编程语言采用了不同的方式来实现线程。许多操作系统都提供了用于创建新线程的 API。这种直接利用操作系统 API 来创建线程的模型常常被称作 1:1 模型,它意味着一个操作系统线程对应一个语言线程。
也有许多编程语言提供了它们自身特有的线程实现,这种由程序语言提供的线程常常被称为绿色线程(green thread),使用绿色线程的语言会在拥有不同数量系统线程的环境下运行它们。为此,绿色线程也被称为 M:N 模型,它表示 M 个绿色线程对应着 N 个系统线程,这里的 M 与 N 不必相等。
由于绿色线程的 M:N 模型需要一个较大的运行时来管理线程,所以 Rust 标准库只提供了 1:1 线程模型的实现。
我们可以调用 thread::spawn 函数来创建线程,它接收一个闭包作为参数,该闭包会包含我们想要在新线程(生成线程)中运行的代码。
创建新线程来打印部分信息,并由主线程打印出另外一部分信息:
|
|
只要这段程序中的主线程运行结束,创建出的新线程就会相应停止,而不管它的打印任务是否完成。
thread::spawn 的返回值类型是一个自持有所有权的 JoinHandle,调用它的 join 方法可以阻塞当前线程直到对应的新线程运行结束。
|
|
move 闭包常常被用来与 thread::spawn 函数配合使用,它允许你在某个线程中使用来自另一个线程的数据。
可以在闭包的参数列表前使用 move 关键字来强制闭包从外部环境中捕获值的所有权。这一技术在我们创建新线程时尤其有用,它可以跨线程地传递某些值的所有权。
通过在闭包前添加 move 关键字,我们会强制闭包获得它所需值的所有权,而不仅仅是基于 Rust 的推导来获得值的借用。
Rust 在标准库中实现了一个名为通道(channel)的编程概念,它可以被用来实现基于消息传递的并发机制。
|
|
函数 mpsc::channel 会返回一个含有发送端与接收端的元组。
- 代码中用来绑定它们的变量名称为 tx 和 rx,这也是在许多场景下发送者与接收者的惯用简写
- mpsc 是英文“multiple producer, single consumer”(多个生产者,单个消费者)的缩写。简单来讲,Rust 标准库中特定的实现方式使得通道可以拥有多个生产内容的发送端,但只能拥有一个消耗内容的接收端
为了让新线程拥有 tx 的所有权,我们使用 move 关键字将 tx 移动到了闭包的环境中。新线程必须拥有通道发送端的所有权才能通过通道来发送消息。
发送端提供了 send 方法来接收我们想要发送的值。这个方法会返回 Result<T,E> 类型的值作为结果;当接收端已经被丢弃而无法继续传递内容时,执行发送操作便会返回一个错误。
通道的接收端有两个可用于获取消息的方法:recv 和 try_recv
- 我们使用的
recv(也就是 receive 的缩写)会阻塞主线程的执行直到有值被传入通道。一旦有值被传入通道,recv 就会将它包裹在Result<T,E>中返回。而如果通道的发送端全部关闭了,recv 则会返回一个错误来表明当前通道再也没有可接收的值。 try_recv方法不会阻塞线程,它会立即返回Result<T,E>:当通道中存在消息时,返回包含该消息的Ok变体;否则便返回Err变体。
send 函数会获取参数的所有权,并在参数传递时将所有权转移给接收者。这可以阻止我们意外地使用已经发送的值,所有权系统会在编译时确保程序的每个部分都是符合规则的。
可以将 rx 视作迭代器,而不再显式地调用 recv 函数。迭代中的代码会打印出每个接收到的值,并在通道关闭时退出循环:
|
|
用多个生产者发送多条消息:
|
|
任何编程语言中的通道都有些类似于单一所有权的概念,因为你不应该在值传递给通道后再次使用它。而基于共享内存的并发通信机制则更类似于多重所有权概念:多个线程可以同时访问相同的内存地址。
互斥体(mutex)是英文 mutual exclusion 的缩写。也就是说,一个互斥体在任意时刻只允许一个线程访问数据。
互斥体是出了名的难用,因为你必须牢记下面两条规则:
- 必须在使用数据前尝试获取锁
- 必须在使用完互斥体守护的数据后释放锁,这样其他线程才能继续完成获取锁的操作
Mutex<T> 是一种智能指针。更准确地说,对 lock 的调用会返回一个名为 MutexGuard 的智能指针。这个智能指针通过实现 Deref 来指向存储在内部的数据,它还会通过实现 Drop 来完成自己离开作用域时的自动解锁操作。这种释放过程会发生在内部作用域的结尾处。因此,我们不会因为忘记释放锁而导致其他线程无法继续使用该互斥体。锁的释放过程是自动发生的。
Rc<T>在跨线程使用时并不安全。当 Rc<T>管理引用计数时,它会在每次调用 clone 的过程中增加引用计数,并在克隆出的实例被丢弃时减少引用计数,但它并没有使用任何并发原语来保证修改计数的过程不会被另一个线程所打断。
我们拥有一种被称为Arc<T>的类型,它既拥有类似于Rc<T>的行为,又保证了自己可以被安全地用于并发场景。它名称中的A代表着原子 (atomic),表明自己是一个原子引用计数(atomically reference counted)类型。
Mutex<T>与Cell系列类型有着相似的功能,它同样提供了内部可变性。