消息队列高手课
物联网(IoT,Internet of Things)可以理解为把所有东西都用互联网给连接起来。
物联网设备,它要实现互相通信,也必须有一套标准的通信协议,MQTT(Message Queuing Telemetry Transport,消息队列遥测传输协议) 就是专门为物联网设备设计的一套标准的消息队列通信协议。使用 MQTT 协议的 IoT 设备,可以连接到任何支持 MQTT 协议的消息队列上,进行通信。
MQTT 的使用场景有什么样的特点?
- MQTT 的客户端都是运行在 IoT 设备上
- 需要支撑海量的 IoT 设备同时在线
- MQTT 它是不支持点对点通信的
- 一般的做法都是,每个客户端都创建一个以自己 ID 为名字的主题,然后客户端来订阅自己的专属主题,用于接收专门发给这个客户端的消息。
IoT 设备的特点:
- IoT 设备最大的特点就是便宜
- IoT 设备的网络连接不稳定
MQTT 协议特点:
- 协议的报文设计上极其的精简
- 增加了心跳和会话的机制
- 加入心跳机制可以让客户端和服务端双方都能随时掌握当前连接状态,一旦发现连接中断,可以尽快地重连
- 会话机制:在服务端来保存会话状态,客户端重连之后就可以恢复之前的会话,继续来收发消息。这样,把复杂度转移到了服务端,客户端的实现就会更简单
MQTT 集群的架构:
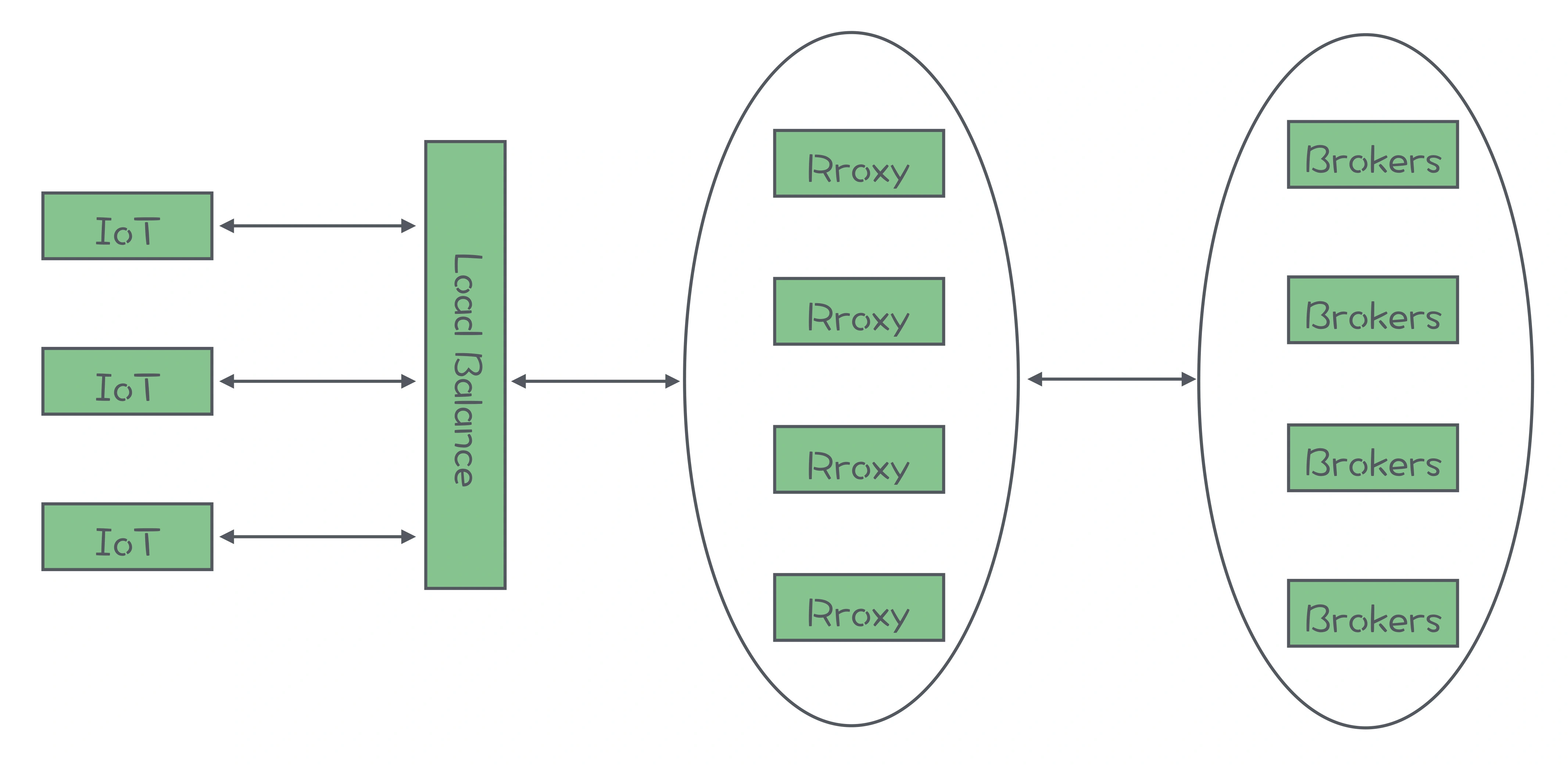 自行构建集群,最关键的技术点就是,通过前置的 Proxy 集群来解决海量连接、会话管理和海量主题这三个问题
自行构建集群,最关键的技术点就是,通过前置的 Proxy 集群来解决海量连接、会话管理和海量主题这三个问题
- 前置 Proxy 负责在 Broker 和客户端之间转发消息,通过这种方式,将海量客户端连接收敛为少量的 Proxy 与 Broker 之间的连接,解决了海量客户端连接数的问题
- 维护会话的实现原理,和 Tomcat 维护 HTTP 会话是一样的
- 另一种方式是,将会话保存在一个外置的存储集群中,比如一个 Redis 集群或者 MySQL 集群
- 对于海量主题,可以在后端部署多组 Broker 小集群,每个小集群分担一部分主题这样的方式来解决
问答区:RabbitMQ,AMQP、MQTT 这三者的关系?
- RabbitMQ:一个开源的消息队列产品;
- AMQP 和 MQTT 都是一种消息队列客户端与服务端交互的标准协议,类似于 HTTP 一样,是一种协议
- RabbitMQ 实现了 AMQP 协议
后端技术面试 38 讲
目前用来改善数据存储能力的主要手段包括:
- 数据库主从复制
- 数据库分片
- NoSQL 数据库
数据库主从复制
MySQL 主要的复制原理是:
- 当应用程序客户端发送一条更新命令到主服务器数据库的时候,数据库会把这条更新命令同步记录到 Binlog 中
- 由另外一个线程从 Binlog 中读取这条日志,通过远程通讯的方式将它复制到从服务器上面去
- 从服务器获得这条更新日志后,将其加入到自己的 Relay Log 中
- 另外一个 SQL 执行线程从 Relay log 中读取这条新的日志,并把它在本地的数据库中重新执行一遍
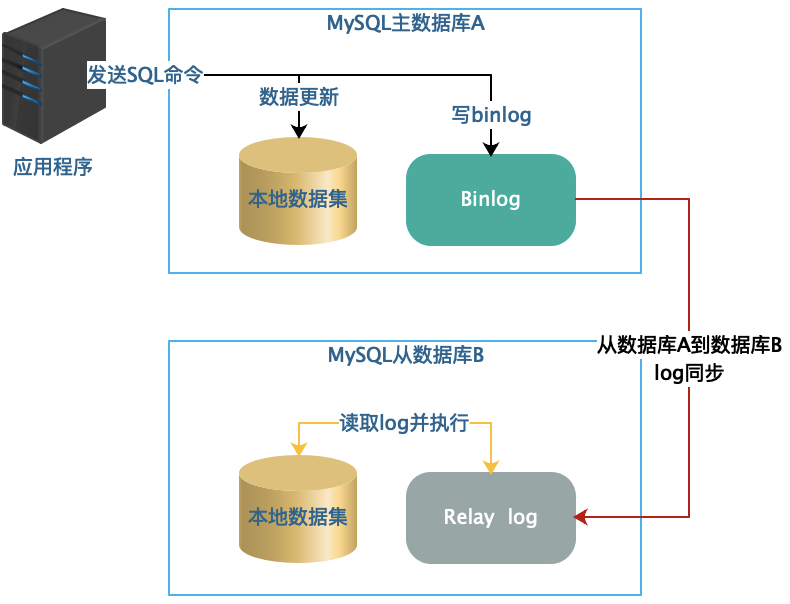 通过数据库主从复制的方式,我们可以实现数据库读写分离。写操作访问主数据库,读操作访问从数据库,使数据库具有更强大的访问负载能力,支撑更多的用户访问。在实践中,通常采用一主多从的数据复制方案,也就是说,一个主数据库将数据复制到多个从数据库,多个从数据库承担更多的读操作压力。
通过数据库主从复制的方式,我们可以实现数据库读写分离。写操作访问主数据库,读操作访问从数据库,使数据库具有更强大的访问负载能力,支撑更多的用户访问。在实践中,通常采用一主多从的数据复制方案,也就是说,一个主数据库将数据复制到多个从数据库,多个从数据库承担更多的读操作压力。
如果主数据库宕机,系统就没法使用了,因此现实中,也会采用 MySQL 主主复制的方案。也就是说,两台服务器互相备份,任何一台服务器都会将自己的 Binlog 复制到另一台机器的 Relay Log 中,以保持两台服务器的数据一致
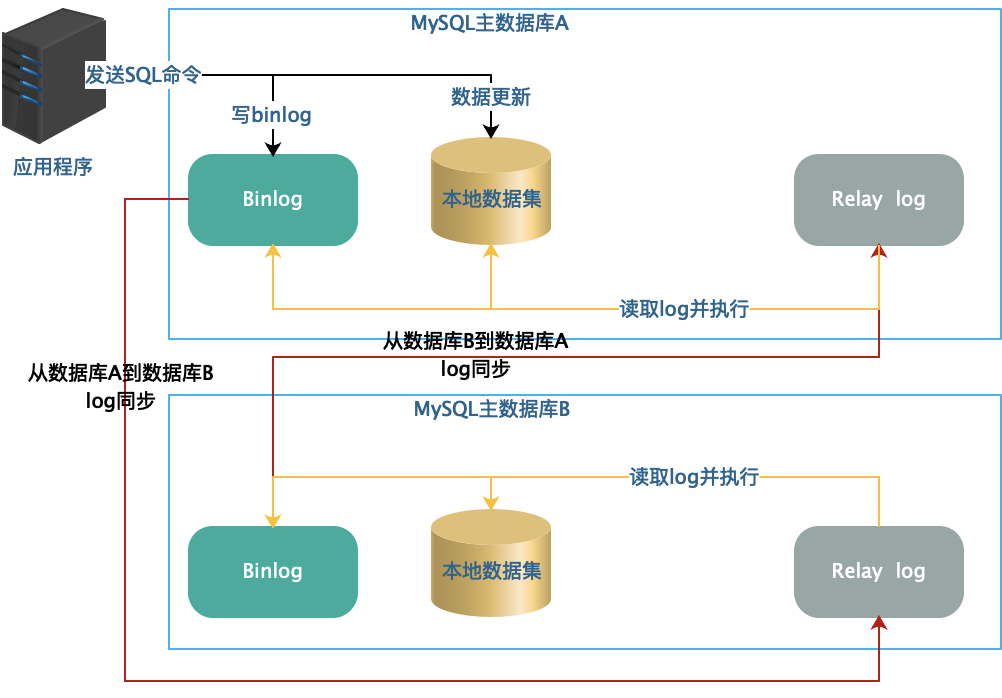 主主复制仅仅用来提升数据写操作的可用性,并不能用来提高写操作的性能。任何时候,系统中都只能有一个数据库作为主数据库,也就是说,所有的应用程序都必须连接到同一个主数据库进行写操作。只有当该数据库宕机失效的时候,才会将写操作切换到另一台主数据库上。
主主复制仅仅用来提升数据写操作的可用性,并不能用来提高写操作的性能。任何时候,系统中都只能有一个数据库作为主数据库,也就是说,所有的应用程序都必须连接到同一个主数据库进行写操作。只有当该数据库宕机失效的时候,才会将写操作切换到另一台主数据库上。
数据库分片
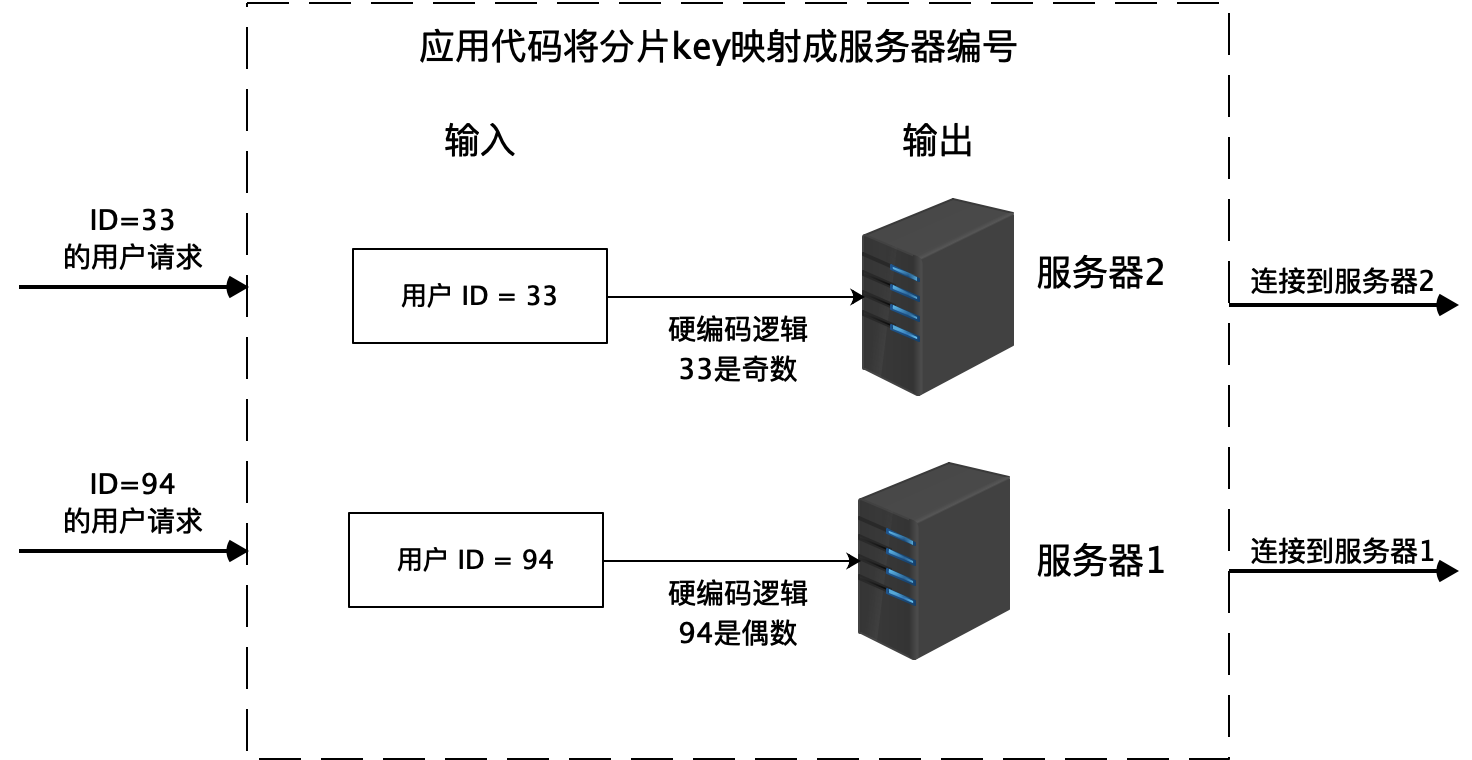
将一张表的数据分成若干片,每一片都包含了数据表中一部分的行记录,然后每一片存储在不同的服务器上,这样一张表就存储在多台服务器上了。
硬编码的方式
使用分布式关系数据库中间件
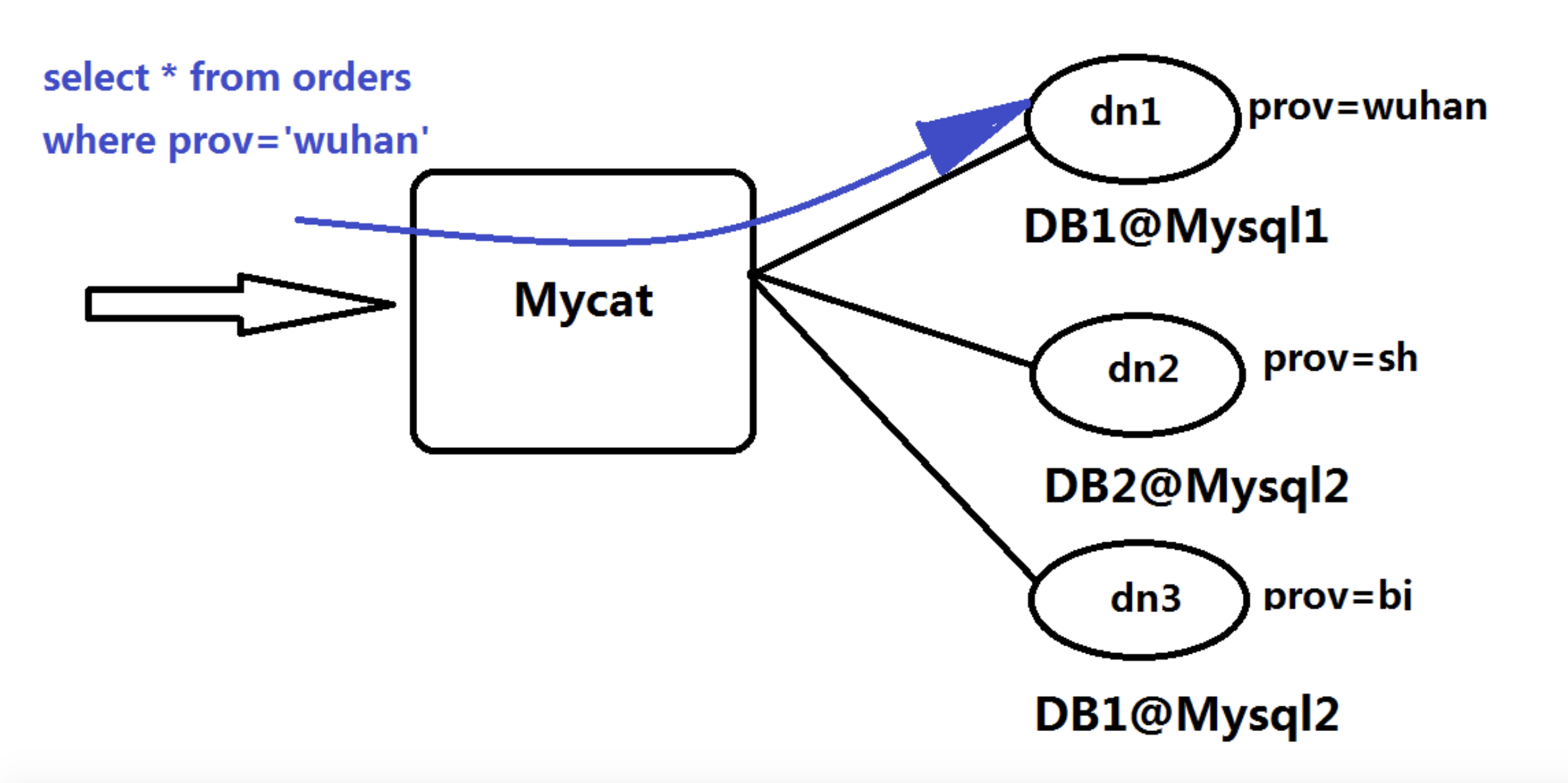
余数 Hash 算法
更常见的数据库分片算法是我们所熟悉的余数 Hash 算法,根据主键 ID 和服务器的数目进行取模计算,根据余数连接相对应的服务器。
关系数据库的混合部署
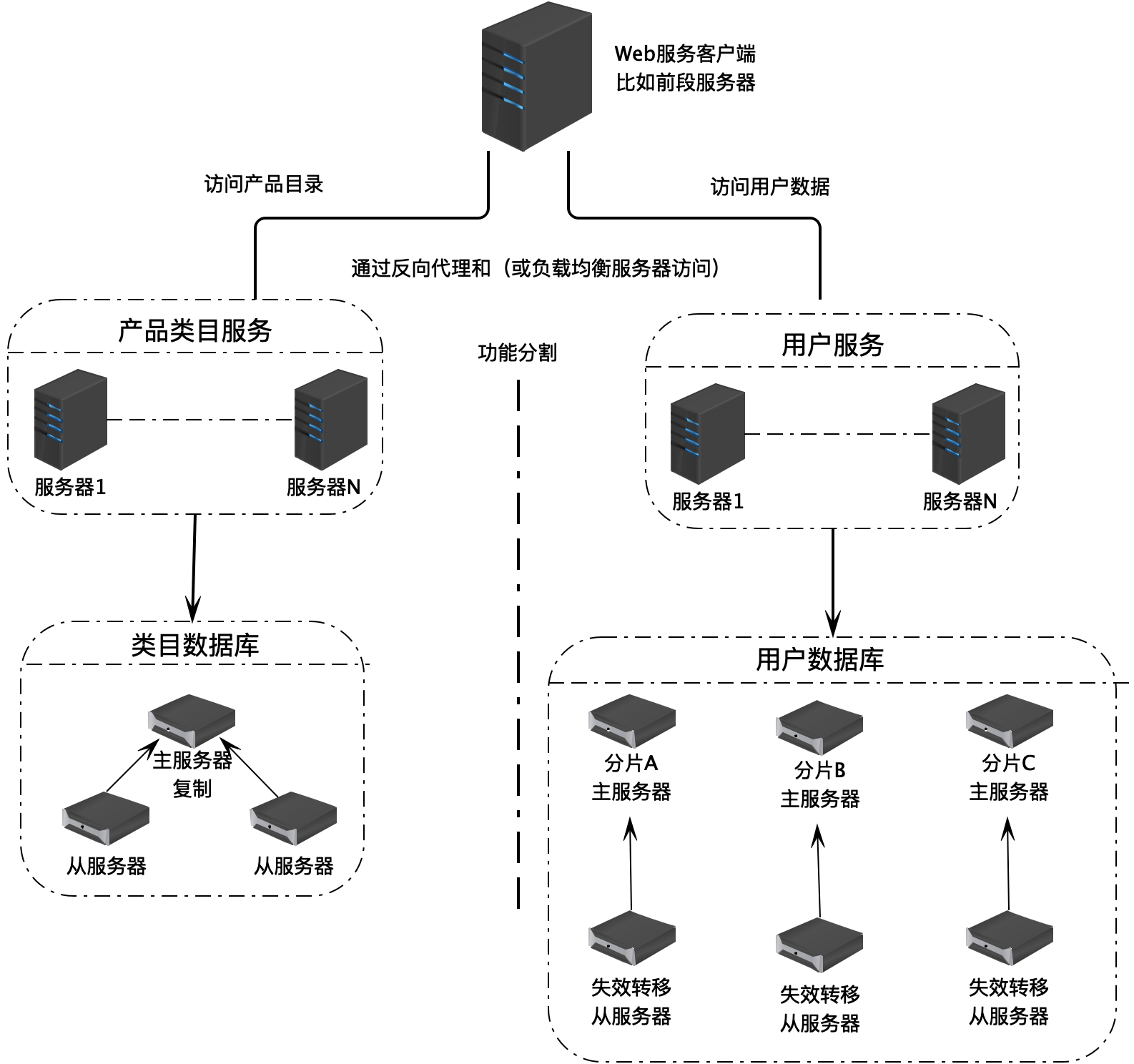
NoSQL 数据库
NoSQL 数据是改善数据存储能力的一个重要手段。
NoSQL 数据库和传统的关系型数据库不同,它主要的访问方式不是使用 SQL 进行操作,而是使用 Key、Value 的方式进行数据访问,所以被称作 NoSQL 数据库。NoSQL 数据库主要用来解决大规模分布式数据的存储问题。
常用的 NoSQL 数据有 Apache HBase,Apache Cassandra 等,Redis 虽然是一个分布式缓存技术产品,但有时候也被归类为 NoSQL 数据库。
关于分布式存储系统有一个著名的 CAP 原理,CAP 原理说:一个提供数据服务的分布式系统无法同时满足数据一致性(Consistency)、可用性(Availability)和分区耐受性(Partition Tolerance)这三个条件。
对于一个分布式系统而言,网络失效一定会发生,也就是说,分区耐受性是必须要保证的,而对于互联网应用来说,可用性也是需要保证的,分布式存储系统通常需要在一致性上做一些妥协和增强。
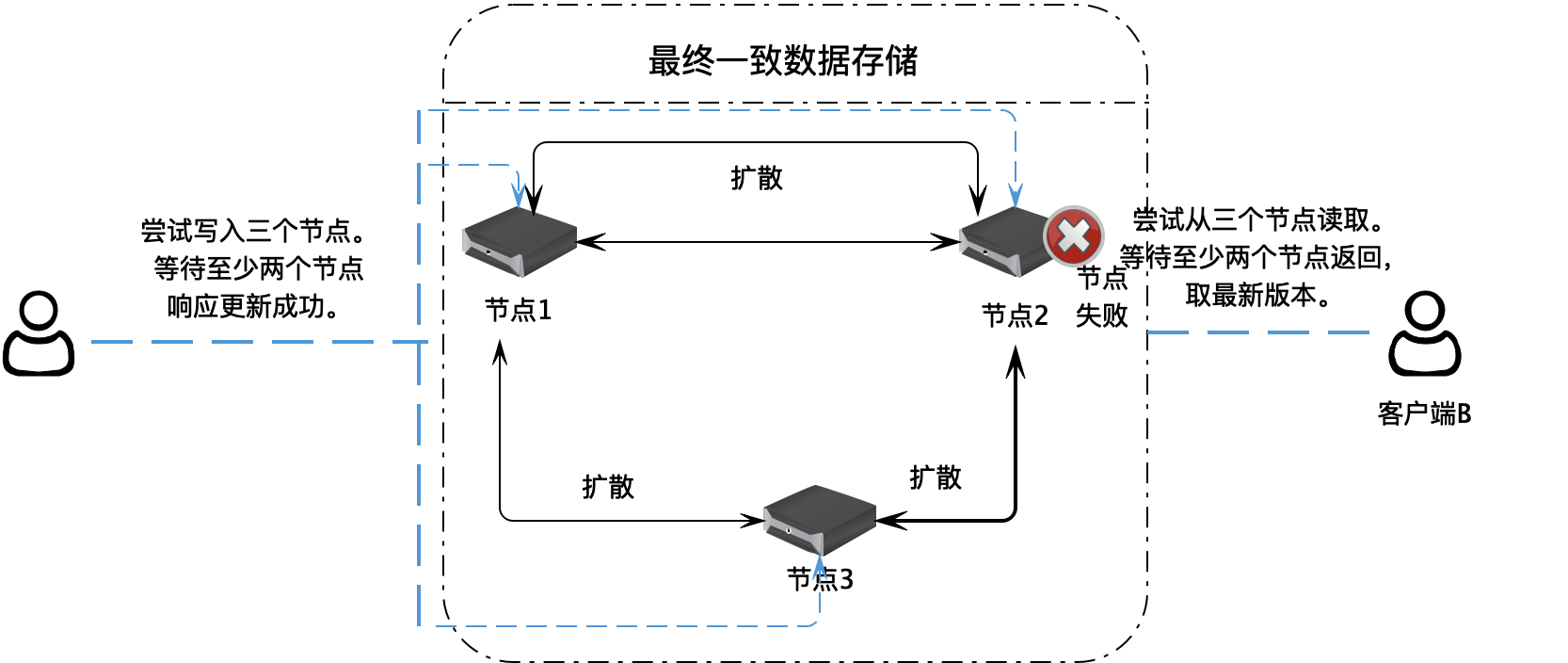
Apache Cassandra 解决数据一致性的方案是:
- 在用户写入数据的时候,将一个数据写入集群中的三个服务器节点,等待至少两个节点响应写入成功
- 用户读取数据的时候,从三个节点尝试读取数据,至少等到两个节点返回数据,并根据返回数据的时间戳,选取最新版本的数据
这样,即使服务器中的数据不一致,但是最终用户还是能得到一个一致的数据,这种方案也被称为最终一致性。
高并发架构实战课
通常的空间邻近算法有以下 4 种
SQL 邻近算法
|
|
地理网格邻近算法
|
|
动态网格算法
不管如何选择网格大小,可能都不合适。因为在陆家嘴即使很小的网格可能就包含近百万的用户,而在可可西里,非常大的网格也包含不了几个用户。
我们希望能够动态设定网格的大小,如果一个网格内用户太多,就把它分裂成几个小网格,小网格内如果用户还是太多,继续分裂更小的网格。
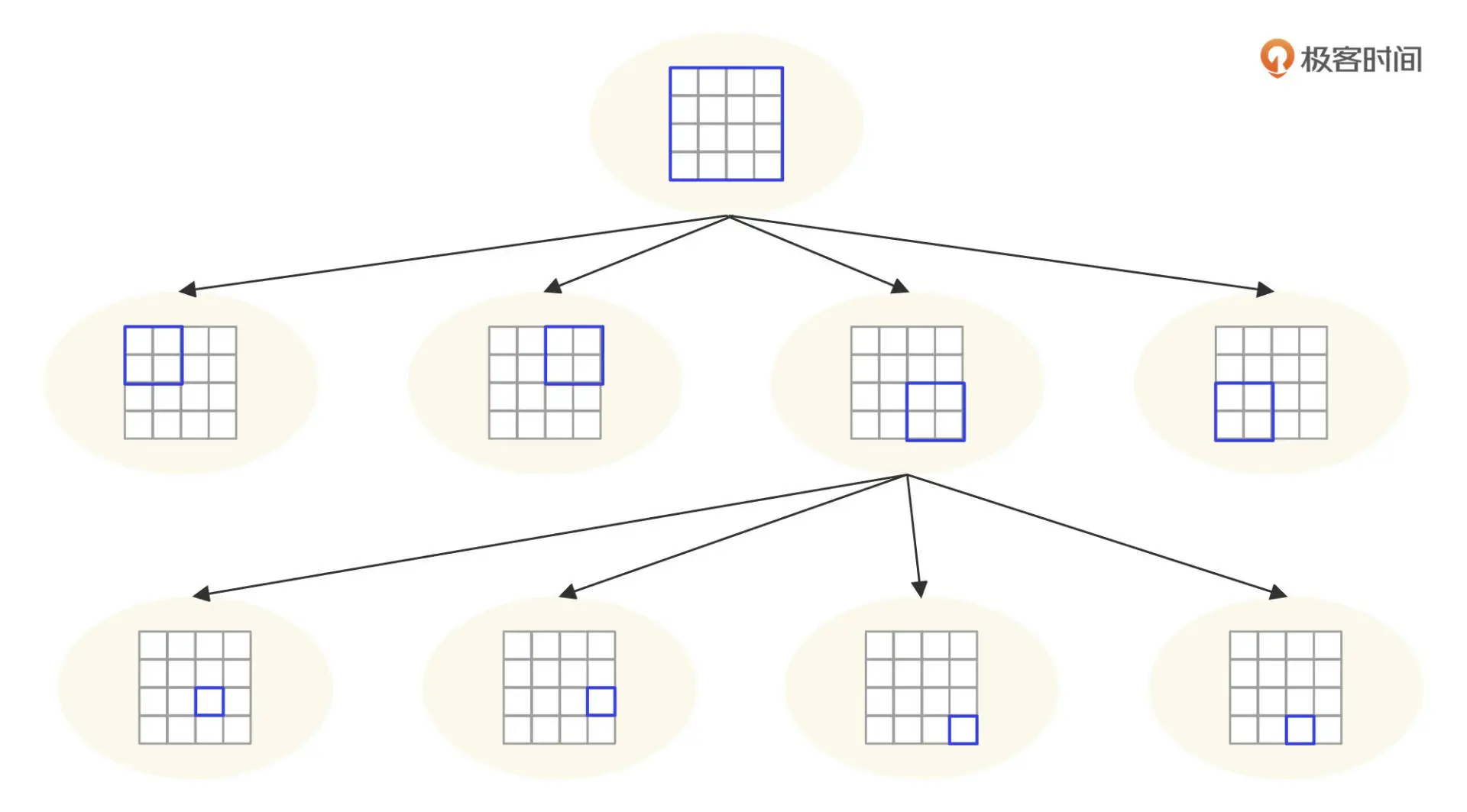
- 这是一个四叉树网格结构,开始的时候整个地球只有一个网格
- 当用户增加,超过阈值(500 个用户)的时候,就分裂出 4 个子树,4 个子树对应父节点网格的 4 个地理子网格
- 将用户根据位置信息重新分配到 4 个子树中
- 如果某个子树中的用户增加,超过了阈值,该子树继续分裂成 4 个子树
我们只需要将 4 叉树所有的叶子节点顺序组成一个双向链表,每个节点在链表上的若干个前驱和后继节点正好就是其地理位置邻近的节点。
动态网格也叫 4 叉树网格,在空间邻近算法中较为常用。
GeoHash 算法
GeoHash 是将网格进行编码,然后根据编码进行 Hash 存储的一种算法。
redis 的 GeoHash 并不会直接用经、纬度做 key,而是采用一种基于 Z 阶曲线的编码方式,将二维的经、纬度,转化为一维的二进制数字,再进行 base32 编码
- 所谓的 Z 阶曲线布局,本质其实就是基于 GeoHash 的二进制排序
- 将这些经过编码的 2 进制数据用跳表存储
- 查找用户的时候,可以快速找到该用户,沿着跳表前后检索,得到的就是邻近的用户
经纬度编码
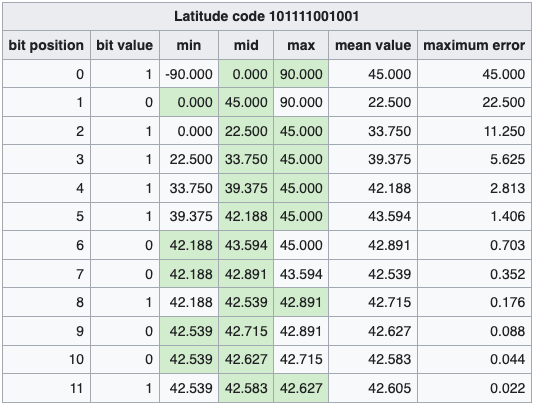
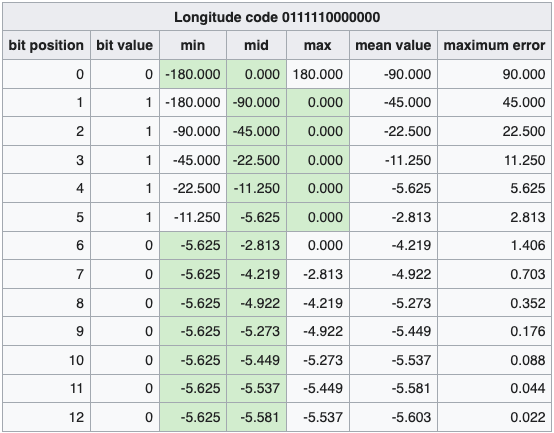
下图表示经、纬度 <43.60411, -5.59041> 的二进制编码过程,最终得到纬度 12 位编码,经度 13 位编码。
经纬度合并
得到两个二进制数后,再将它们合并成一个二进制数。合并规则是,从第一位开始,奇数位为经度,偶数位为纬度,上面例子合并后的结果为 01101 11111 11000 00100 00010 ,共 25 位二进制数。
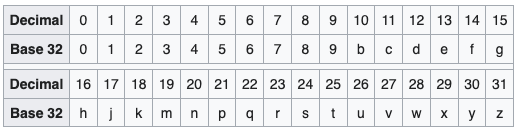
Base32 编码
将 25 位二进制数划分成 5 组,每组 5 个二进制数,对应的 10 进制数是 0-31,采用 Base32 编码,可以得到一个 5 位字符串,Base32 编码表如下。
编码计算过程:
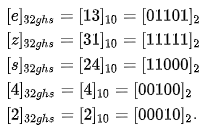
存储
最后得到一个字符串“ezs42”,作为 Hash 表的 key。25 位二进制的 GeoHash 编码,其误差范围大概 2.4 公里,即对应一个 2.4km x 2.4km 的网格。网格内的用户都作为 value 放入到 Hash 表中。
Redis 中的 GeoHash 并没有用 Hash 表存储,而是用跳表存储。
Redis 使用 52 位二进制的 GeoHash 编码,误差范围 0.6 米。
架构和算法通常是一个复杂系统的一体两面,架构是关于整体系统是如何组织起来的,而算法则是关于核心功能如何处理的。
Rust 权威指南
状态模式(state pattern)是一种面向对象的设计模式,它的关键特点是,一个值拥有的内部状态由数个状态对象(state object)表达而成,而值的行为则随着内部状态的改变而改变。
使用状态模式意味着在业务需求发生变化时我们不需要修改持有状态对象的值,或者使用这个值的代码。我们只需要更新状态对象的代码或增加一些新的状态对象,就可以改变程序的运转规则。
动态派发通过牺牲些许的运行时性能赋予了代码更多的灵活性。你可以利用这种灵活性来实现有助于改善代码可维护性的面向对象模式。
由于 Rust 具有所有权等其他面向对象语言没有的特性,所以面向对象的模式仅仅是一种可用的选项,而并不总是最佳实践方式。
我们为什么睡觉
睡眠缺乏时形成的记忆是较弱的记忆,会迅速消散。
睡眠缺乏是一种深入渗透、腐蚀的力量,会使你大脑中制造记忆的器官逐渐衰弱,从而妨碍你建立持久的记忆印迹。
如果你在学习之后的第一个晚上没有睡觉,那么即使你之后得到了很多的 “补充”睡眠,你也没有机会巩固这些记忆了。
对于记忆来说,睡眠并不像银行。你不能把债务累积起来,并希望在之后的日子里还清。
睡眠障碍在阿尔茨海默病发病的几年前就已经存在了,这表明它有可能是病情的早期预警信号,甚至是发病的起因。
睡眠障碍和阿尔茨海默病以一种自我实现的负螺旋形式相互作用,可以引发、加重病情。
成年阶段睡得太少会显著增加患上阿尔茨海默病的风险。
睡眠质量差,心脏就不健康。
心脏在睡眠剥夺的重压下遭受如此巨大的痛苦的部分原因在于血压。
除了心率过快和血压增高之外,睡眠缺失会进一步侵蚀那些紧张的血管,尤其是那些本身用于为心脏供血的血管,它们叫作冠状动胁。
交感神经系统是个具有强烈活性化、刺激性,甚至煽动性的系统。必要的话,它会在几秒钟内在全身发动原始的战斗或逃跑压力反应。
除了少数例外,每个研究睡眠不足对人体影响的实验中,都观察到了交感神经系统的过度活跃。