Rust 权威指南
在 Rust 中,迭代器是惰性的(layzy)。这也就意味着创建迭代器后,除非你主动调用方法来消耗并使用迭代器,否则它们不会产生任何的实际效果。
Iterator trait 只要求实现者手动定义一个方法:next 方法,它会在每次被调用时返回一个包裹在 Some 中的迭代器元素,并在迭代结束时返回 None。
iter 方法生成的是一个不可变引用的迭代器,我们通过 next 取得的值实际上是指向动态数组中各个元素的不可变引用。
- 如果你需要创建一个取得 v1 所有权并返回元素本身的迭代器,那么你可以使用 into_iter 方法。
- 如果你需要可变引用的迭代器,那么你可以使用 iter_mut 方法。
Iterator trait 提供了多种包含默认实现的方法,这些方法中的一部分会在它们的定义中调用 next 方法,调用 next 的方法也被称为消耗适配器 (consuming adaptor),因为它们同样消耗了迭代器本身。
Iterator trait 还定义了另外一些被称为迭代器适配器 (iterator adaptor) 的方法,这些方法可以使你将已有的迭代器转换成其他不同类型的迭代器。
函数式编程风格倾向于在程序中最小化可变状态的数量来使代码更加清晰。
迭代器可以让开发者专注于高层的业务逻辑,而不必陷入编写循环、维护中间变量这些具体的细节中。通过高层抽象去消除一些惯例化的模板代码,也可以让代码的重点逻辑(例如 filter 方法的过滤条件)更加突出。
陈天 · Rust 编程第一课
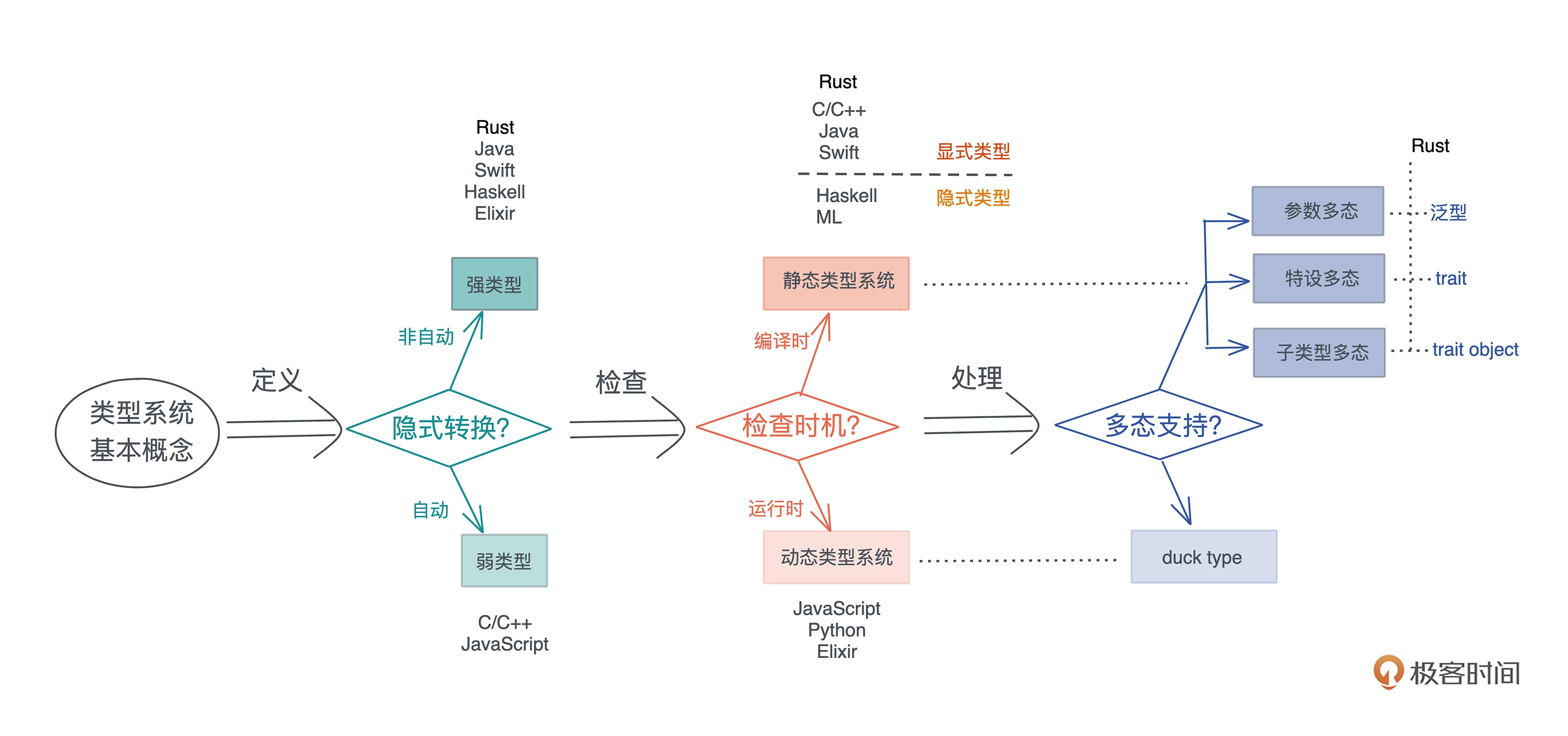
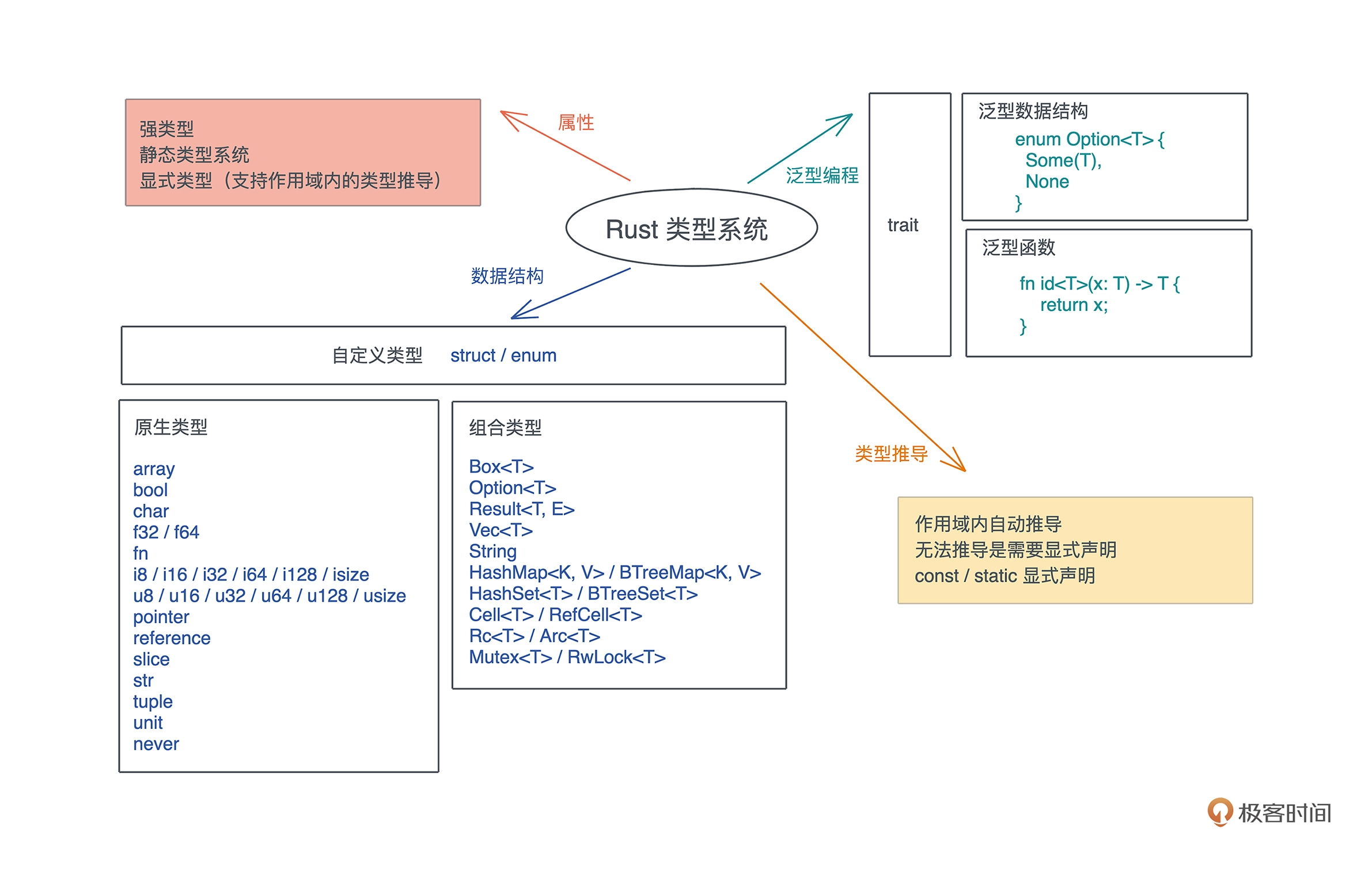
作为一门语言的核心要素,类型系统很大程度上塑造了语言的用户体验以及程序的安全性。
在机器码的世界中,没有类型而言,指令仅仅和立即数或者内存打交道,内存中存放的数据都是字节流。
类型系统就是,对类型进行定义、检查和处理的系统。
- 按定义后类型是否可以隐式转换,可以分为强类型和弱类型。
- 按类型检查的时机,在编译时检查还是运行时检查,可以分为静态类型系统和动态类型系统。
- 对于静态类型系统,还可以进一步分为显式静态和隐式静态
在类型系统中,多态是一个非常重要的思想,它是指在使用相同的接口时,不同类型的对象,会采用不同的实现。
- 对于动态类型系统,多态通过鸭子类型(duck typing)实现
- 对于静态类型系统,多态可以通过参数多态(parametric polymorphism)、特设多态(adhoc polymorphism)和子类型多态(subtype polymorphism)实现。
- 参数多态是指,代码操作的类型是一个满足某些约束的参数,而非具体的类型。
- 特设多态是指同一种行为有多个不同实现的多态。
- 比如加法,可以 1+1,也可以是 “abc” + “cde”、matrix1 + matrix2、甚至 matrix1 + vector1。
- 在面向对象编程语言中,特设多态一般指函数的重载。
- 子类型多态是指,在运行时,子类型可以被当成父类型使用。
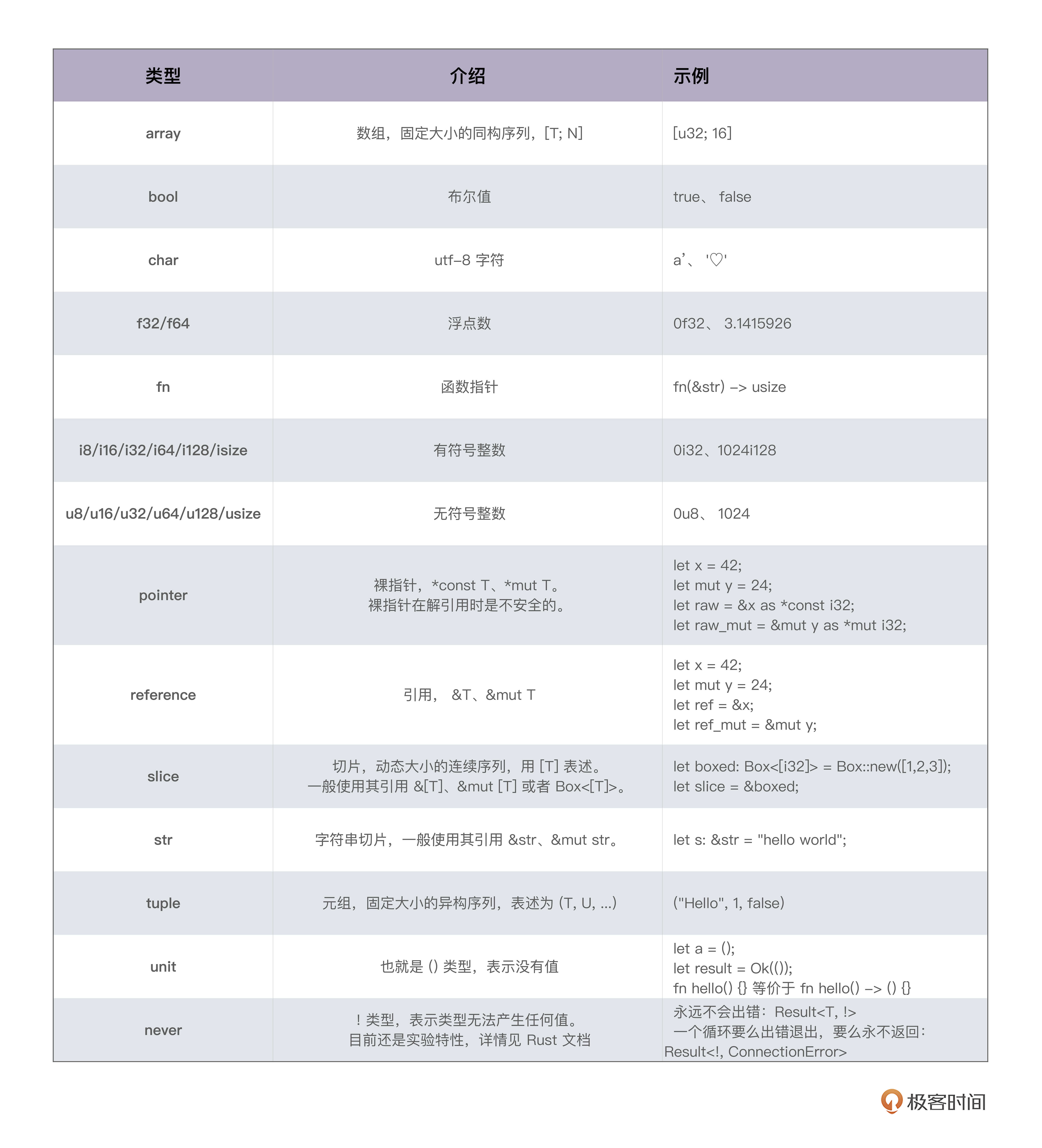
 在 Rust 中,对于一个作用域,无论是 if / else / for 循环,还是函数,最后一个表达式的返回值就是作用域的返回值,如果表达式或者函数不返回任何值,那么它返回一个 unit() 。unit 是只有一个值的类型,它的值和类型都是 () 。
在 Rust 中,对于一个作用域,无论是 if / else / for 循环,还是函数,最后一个表达式的返回值就是作用域的返回值,如果表达式或者函数不返回任何值,那么它返回一个 unit() 。unit 是只有一个值的类型,它的值和类型都是 () 。
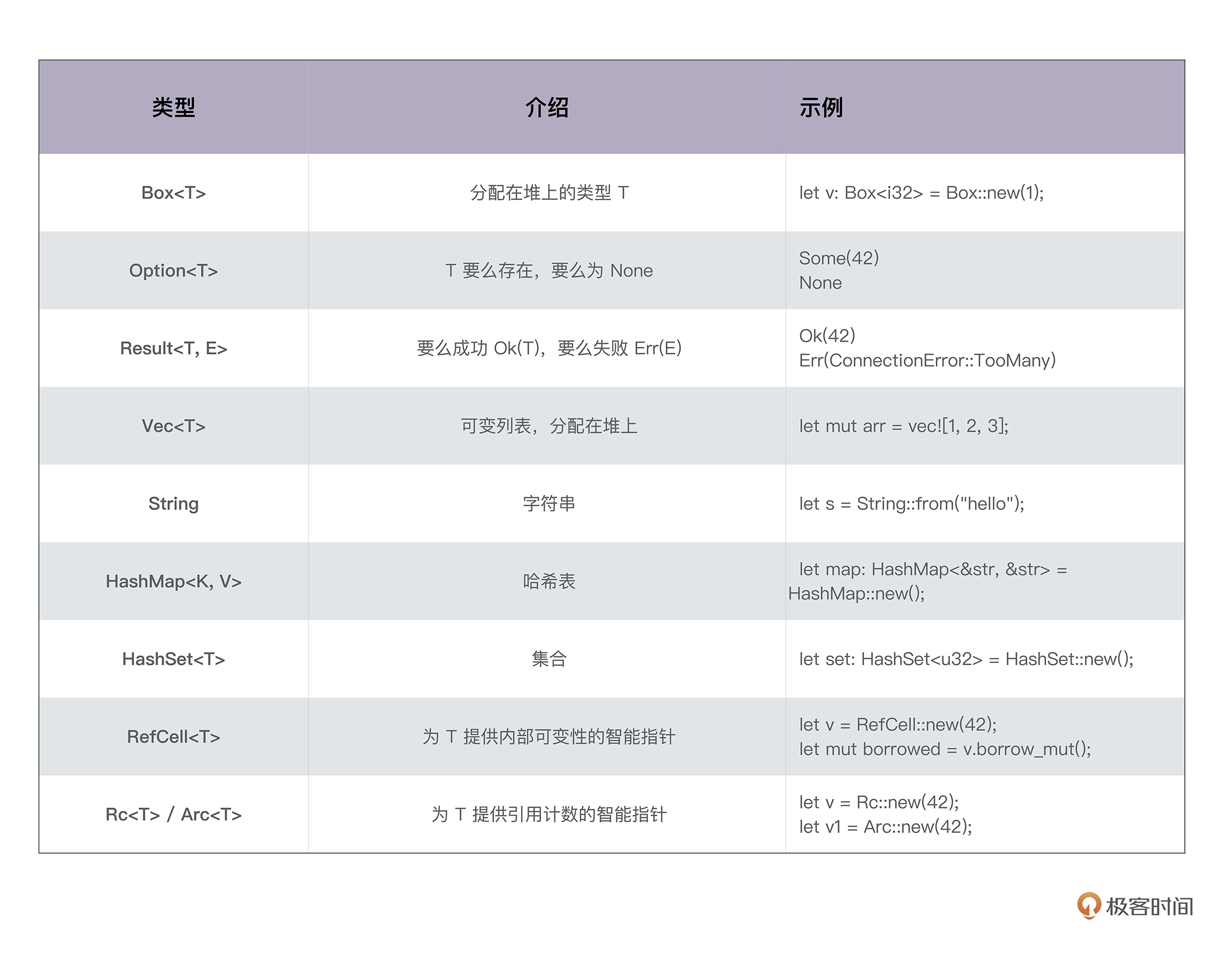
 Rust 组合类型:
Rust 组合类型:
 在一个作用域之内,Rust 可以根据变量使用的上下文,推导出变量的类型,这样我们就不需要显式地进行类型标注了。
在一个作用域之内,Rust 可以根据变量使用的上下文,推导出变量的类型,这样我们就不需要显式地进行类型标注了。
在泛型函数后使用 :: <T> 来强制使用类型 T,这种写法被称为 turbofish:
|
|
函数和泛型的类比:
- 函数,是把重复代码中的参数抽取出来,使其更加通用,调用函数的时候,根据参数的不同,我们得到不同的结果;
- 泛型,是把重复数据结构中的参数抽取出来,在使用泛型类型时,根据不同的参数,我们会得到不同的具体类型。
在 Rust 里,生命周期标注也是泛型的一部分,一个生命周期 ‘a 代表任意的生命周期,和 T 代表任意类型是一样的。
Cow(Clone-on-Write)是 Rust 中一个很有意思且很重要的数据结构。它就像 Option 一样,在返回数据的时候,提供了一种可能:要么返回一个借用的数据(只读),要么返回一个拥有所有权的数据(可写)。
|
|
在表述泛型参数的约束时,Rust 允许两种方式,两种方法都可以,且可以共存
- 类似函数参数的类型声明,用 “:” 来表明约束,多个约束之间用 + 来表示;
- 使用 where 子句,在定义的结尾来表明参数的约束。
?Sized 是一种特殊的约束写法,? 代表可以放松问号之后的约束。
这里对 B 的三个约束分别是:
- 生命周期
'a - 长度可变
?Sized - 符合
ToOwned trait
对于泛型函数,Rust 会进行单态化(Monomorphization) 处理,也就是在编译时,把所有用到的泛型函数的泛型参数展开,生成若干个函数。
|
|
单态化的好处是,泛型函数的调用是静态分派(static dispatch),在编译时就一一对应,既保有多态的灵活性,又没有任何效率的损失,和普通函数调用一样高效。
单态化有很明显的坏处,就是编译速度很慢,一个泛型函数,编译器需要找到所有用到的不同类型,一个个编译。
后端技术面试 38 讲
数组是最常用的数据结构,创建数组必须要内存中一块连续的空间,并且数组中必须存放相同的数据类型。
Hash 表的物理存储其实是一个数组,如果我们能够根据 Key 计算出数组下标,那么就可以快速在数组中查找到需要的 Key 和 Value。
消息队列高手课
作为一款及格的消息队列产品,必须具备的几个特性包括:
- 消息的可靠传递:确保不丢消息;
- Cluster:支持集群,确保不会因为某个节点宕机导致服务不可用,当然也不能丢消息;
- 性能:具备足够好的性能,能满足绝大多数场景的性能要求。
其他特性:
- 开源
- 流行并且社区活跃
RabbitMQ
RabbitMQ 一个比较有特色的功能是支持非常灵活的路由配置,和其他消息队列不同的是,它在生产者(Producer)和队列(Queue)之间增加了一个 Exchange 模块,可以理解为交换机。
这个 Exchange 模块的作用和交换机也非常相似,根据配置的路由规则将生产者发出的消息分发到不同的队列中。路由的规则也非常灵活,甚至你可以自己来实现路由规则。
RabbitMQ 的几个问题:
- RabbitMQ 对消息堆积的支持不好
- 性能差
- 编程语言 Erlang,小众、学习曲线陡峭
RocketMQ
RocketMQ 就像一个品学兼优的好学生,有着不错的性能,稳定性和可靠性,具备一个现代的消息队列应该有的几乎全部功能和特性,并且它还在持续的成长中。
RocketMQ 对在线业务的响应时延做了很多的优化,大多数情况下可以做到毫秒级的响应,如果你的应用场景很在意响应时延,那应该选择使用 RocketMQ。
Kafka
Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域,几乎所有的相关开源软件系统都会优先支持 Kafka。
Kafka 使用 Scala 和 Java 语言开发,设计上大量使用了批量和异步的思想,这种设计使得 Kafka 能做到超高的性能。
Kafka 不太适合在线业务场景:Kafka 的同步收发消息的响应时延比较高,因为当客户端发送一条消息的时候,Kafka 并不会立即发送出去,而是要等一会儿攒一批再发送,在它的 Broker 中,很多地方都会使用这种“先攒一波再一起处理”的设计。当你的业务场景中,每秒钟消息数量没有那么多的时候,Kafka 的时延反而会比较高。
消息队列选择建议:
- 如果说,消息队列并不是你将要构建系统的主角之一,你对消息队列功能和性能都没有很高的要求,只需要一个开箱即用易于维护的产品,我建议你使用 RabbitMQ。
- 如果你的系统使用消息队列主要场景是处理在线业务,比如在交易系统中用消息队列传递订单,那 RocketMQ 的低延迟和金融级的稳定性是你需要的。
- 如果你需要处理海量的消息,像收集日志、监控信息或是前端的埋点这类数据,或是你的应用场景大量使用了大数据、流计算相关的开源产品,那 Kafka 是最适合你的消息队列。